


Built a middleware to catch LLM hallucinations in RAG apps
I've been working on RAG applications lately and the biggest issue I keep running into is trust. The models sound confident, but the facts are often slightly off, and manually checking logs is not sustainable.
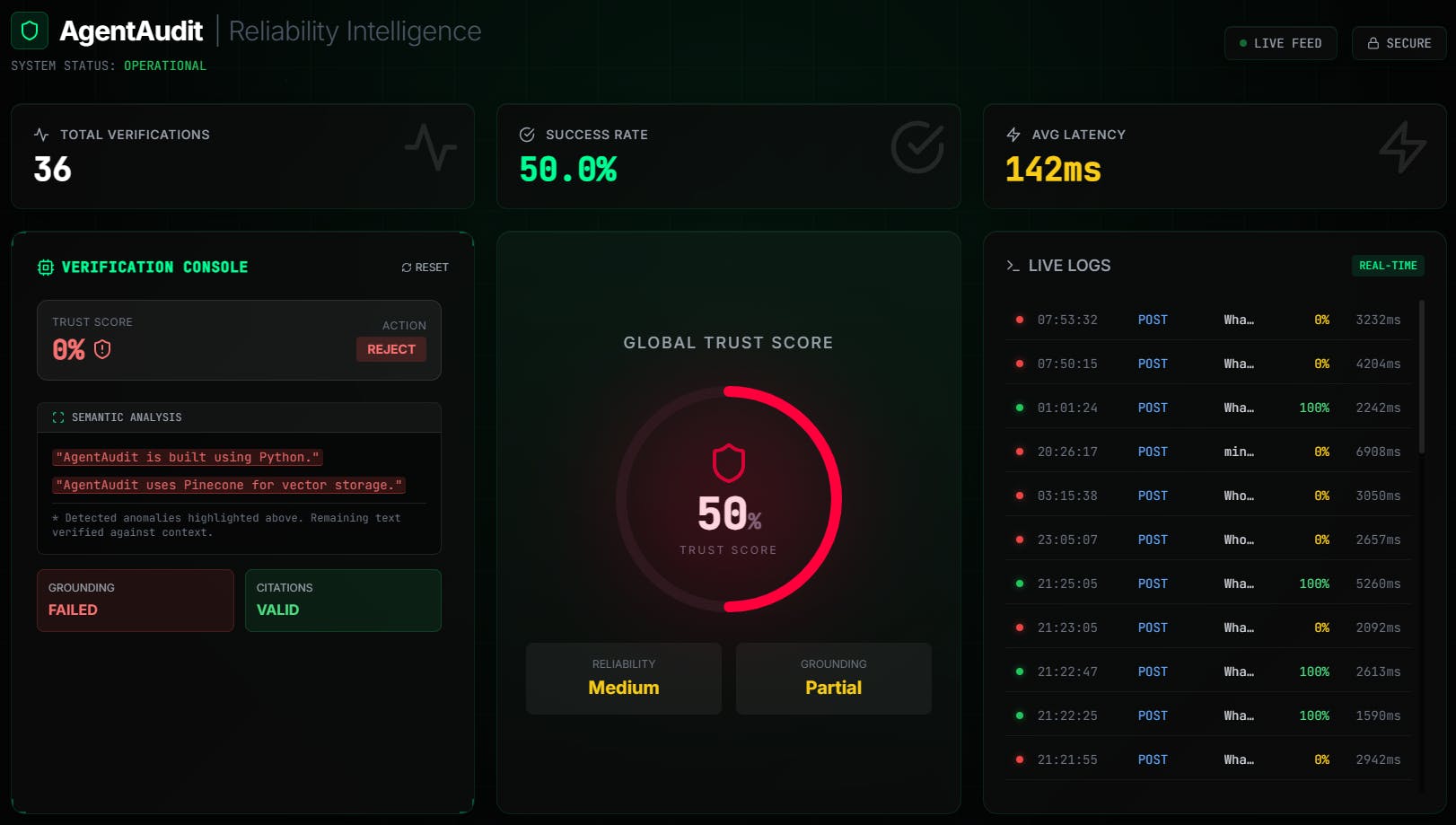
So I built AgentAudit to solve this for my own projects.
It is a middleware API built with Node.js and TypeScript that sits between your LLM and the user. It uses PostgreSQL and pgvector to cross-reference the AI's response against your source documents in real-time. If the "Trust Score" is too low, it flags the response before it reaches the frontend.
I launched it today and I'm looking for feedback on the architecture and the detection logic.
How do you currently handle QA for your agents? Do you have automated checks or are you doing manual review?
Check it out here: [https://www.producthunt.com/products/agentaudit]
Thanks, Jake
Replies