
Launching today

Jentic Mini
Give your AI agents safe access to 10,000+ APIs
292 followers
Give your AI agents safe access to 10,000+ APIs
292 followers
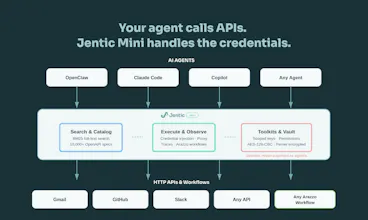
Building agents that call real APIs is painful. You end up hardcoding auth, juggling secrets in prompts, and writing glue code for every service. Jentic Mini is a self-hosted, open-source API execution layer that sits between your agent and the outside world. Your agent says what it wants to do. Jentic Mini finds the right API from a catalog of 10,000+, injects credentials at runtime, and brokers the request. Secrets never touch the agent.






the credential injection at runtime is brilliant. how does the credential management work in practice? does it support role-based access for different agents? congrats on your launch!
@piotr_ratkowski Thanks! The credential management is designed to be invisible to agents by design.
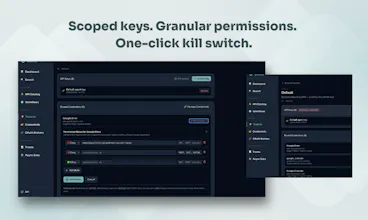
Credentials are Fernet-encrypted at rest in a local SQLite vault with write-only semantics. Once stored, the plaintext value is never returned by any API call. Agents never hold secrets. They hold a scoped toolkit key (tk_-prefixed) which the broker uses at request time to look up and inject the right credential for the upstream API being called.
Role-based access comes through toolkits. Create one per agent, each with its own key, IP restrictions, and allow/deny policy rules evaluated against the Capability ID (METHOD/host/path). Give one agent read-only access to Stripe, another full access, or deny DELETE/* across the board. A compromised agent key exposes only its scoped toolkit. No blast radius to other agents or credentials. And when adding we have a least-privilege approach. It's read-only operations by default.
When needed agents can also escalate. If they need access they don't currently have, they submit a permission request with a reason. You approve or deny it in the UI. The agent cand the workflow, but the human stays in the loop.
the versioned workflow part is interesting
once agents start registering more of their own flows back into the system, how do you stop the catalog from turning into a pile of almost-duplicate specs over time?
@artem_kosilov Thanks, we think about that topic a lot.
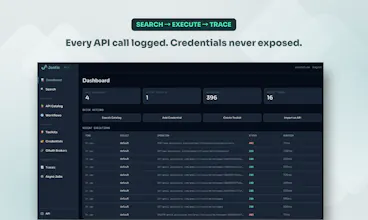
The first line of defence is search quality. The commercial variant uses a semantic search model that's significantly better at surfacing what already exists, so agents find the right workflow before they'd ever think to register a new one. You won't run that locally, but even the BM25 search in Jentic Mini benefits from the rich semantic metadata baked into each Arazzo workflow document, so discovery is still solid.
Agents can register workflows directly. We're adding human-in-the-loop review and similarity checking as part of the process, so near-duplicates get caught before they entrench.
The underlying structure helps too: workflows are registered docs following the Arazzo Specification standard with slug-based identity, so re-registering the same intent converges rather than forks. The format forces explicitness and you can diff two workflows to decide whether it's genuinely new or just an update.
Clipboard Canvas v2.0
The ability to avoid hardcoding secrets and dynamically inject creds part is genius, it saves so much headache. What’s been the biggest challenge in curating the API catalog, especially in keeping it updated and reliable?
@trydoff Thanks! The credential injection piece is where most setups fall apart, so glad it resonates.
The catalog challenge is real and multi-layered. The biggest headache? Invalid or incomplete OpenAPI descriptions. A lot of published specs are technically valid but practically unusable: wrong base URLs, missing auth schemes, undocumented parameters. Several of us have been deep in OpenAPI tooling for years, which helps us spot and fix issues fast. Where we need to upgrade or patch specs, we lean on the OAI Overlay spec rather than forking definitions, which keeps the chain clean.
Sourcing is the other piece: finding the canonical definition, tracking it, and knowing when it changes. We've built polling mechanisms for that, but the longer play is working directly with API providers on more integrated sync processes. That's where we're investing now.
For APIs where we only have docs and no reference definition, we use our jentic-api skill to generate the OpenAPI from the documentation. Not perfect, but it gets us 80% of the way there fast.
Community contributions are also helping in keeping coverage broad and current. If anyone here wants to help with a specific API, we'd love the input.
Research Buddy
Very cool. Will try w my hetzner vps. Openrouter but not just for LLMs!
@ronankmcgovern thanks! All feedback welcome. Check out https://github.com/jentic/jentic-quick-claw for a quick start guide and some instructions for hetzner vps
Congratulations on the launch 🎉
@shubham_pratap Thank you!