
Launched this week

Jentic Mini
Give your AI agents safe access to 10,000+ APIs
485 followers
Give your AI agents safe access to 10,000+ APIs
485 followers
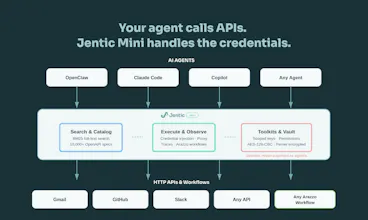
Building agents that call real APIs is painful. You end up hardcoding auth, juggling secrets in prompts, and writing glue code for every service. Jentic Mini is a self-hosted, open-source API execution layer that sits between your agent and the outside world. Your agent says what it wants to do. Jentic Mini finds the right API from a catalog of 10,000+, injects credentials at runtime, and brokers the request. Secrets never touch the agent.






10,000+ APIs is wild - how do you handle auth across all of them? Storing credentials per agent sounds like a nightmare, and rate limit management across a fleet of agents hitting the same API is a real problem I've run into.
@mykola_kondratiuk Both are challenges, and here's where we are.
Firstly, we don't store a credential per API up front. You only add credentials for the APIs you actually use. The broker handles injection regardless of auth pattern: bearer token, API key header, basic auth, OAuth. And if an API's OpenAPI document has wrong or missing security schemes (more common than it should be), agents can register a correction via our security scheme overlay flywheel (using the Overlay Spec from OAI). Those overlays get auto-confirmed on the first successful 2xx and are reused by all agents in that toolkit going forward.
Longer term, the right fix is better specs at source. We give providers the tools to get there: our AI-readiness scorecard scores APIs across six dimensions including security scheme completeness, and the underlying open source framework is available for anyone to run themselves. Validity and usability are not the same thing. The flywheel is a workaround for today. Better specs are the answer for tomorrow.
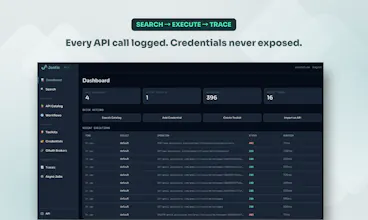
Jentic Mini doesn't do rate limit management yet on a per API basis. It's on the roadmap. Every call routes through the broker as a single chokepoint, so you have full trace visibility into who's hitting what. What we do prevent is the problem you've likely hit before: N agents with N hardcoded keys all hammering the same API independently. Credentials are centralised. You can bind the same credential to multiple toolkits, so all agents route through one provider API token if you want to manage quota centrally. Rate limiting enforcement and per-toolkit quota controls are next. If that's a blocker for your use case, keen to hear the specifics.
Makes sense - context bloat from including all tools is a real issue when you're chaining calls. Selective loading keeps the model focused.
Hey everyone, Jake here from the Jentic team! 👋
We're absolutely delighted to see such a great response today on Product Hunt.
We built Jentic Mini to solve a problem that almost anyone building AI agents has hit: how to let an agent call real APIs without leaking credentials or losing control. Instead of hardcoding keys into prompts or writing endless bespoke wrapper functions, Jentic Mini gives you a self-hosted API execution layer. It securely handles the credentials (your agent never sees them) and lets your agent instantly search and execute against 10,000+ API specs right out of the box.
If you have any questions, feedback, or run into any rough edges, just let us know below. The Jentic team is on-hand all day and happy to help.
the versioned workflow part is interesting
once agents start registering more of their own flows back into the system, how do you stop the catalog from turning into a pile of almost-duplicate specs over time?
@artem_kosilov Thanks, we think about that topic a lot.
The first line of defence is search quality. The commercial variant uses a semantic search model that's significantly better at surfacing what already exists, so agents find the right workflow before they'd ever think to register a new one. You won't run that locally, but even the BM25 search in Jentic Mini benefits from the rich semantic metadata baked into each Arazzo workflow document, so discovery is still solid.
Agents can register workflows directly. We're adding human-in-the-loop review and similarity checking as part of the process, so near-duplicates get caught before they entrench.
The underlying structure helps too: workflows are registered docs following the Arazzo Specification standard with slug-based identity, so re-registering the same intent converges rather than forks. The format forces explicitness and you can diff two workflows to decide whether it's genuinely new or just an update.
the credential injection at runtime is brilliant. how does the credential management work in practice? does it support role-based access for different agents? congrats on your launch!
@piotr_ratkowski Thanks! The credential management is designed to be invisible to agents by design.
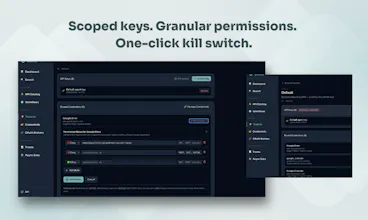
Credentials are Fernet-encrypted at rest in a local SQLite vault with write-only semantics. Once stored, the plaintext value is never returned by any API call. Agents never hold secrets. They hold a scoped toolkit key (tk_-prefixed) which the broker uses at request time to look up and inject the right credential for the upstream API being called.
Role-based access comes through toolkits. Create one per agent, each with its own key, IP restrictions, and allow/deny policy rules evaluated against the Capability ID (METHOD/host/path). Give one agent read-only access to Stripe, another full access, or deny DELETE/* across the board. A compromised agent key exposes only its scoped toolkit. No blast radius to other agents or credentials. And when adding we have a least-privilege approach. It's read-only operations by default.
When needed agents can also escalate. If they need access they don't currently have, they submit a permission request with a reason. You approve or deny it in the UI. The agent cand the workflow, but the human stays in the loop.
@seanblanchfield1 @char0n
Hey guys, awesome tool.
I’m a researcher for the H1Gallery newsletters (you can google us).
We’re featuring Jentic in our April 3 issue. H1Gallery highlights excellent homepage headlines, and “10,000+ APIs. Zero credential exposure.” really stood out to us, love the clarity and contrast.
Would love to include a quick comment from your team about the copywriting strategy behind that headline and the broader messaging. Totally optional of course. the feature is happening either way, we'll see you in the April 3rd edition!
Thanks, really appreciate it. I dropped @seanblanchfield1 a comment on X as well.
Thank you in advance for your time and congrats on the launch!
Jentic Mini
Hi@michael_henderson550 - thanks for reaching out! Let me know what your email is and we'll be in touch?
@neorama Sure thing. You can reach me at authormichaelh@gmail.com . Thank you for responding!
What should you do if there is no clear data to retrieve via API, and the agent needs to log in on its own and analyze the content after logging in using AI?
@natalia_iankovych Are you referring to scenarios where there's no easy to find API for a third-party system?
Having the agent log in to do the work can lead to brittle automation (especially if you're not in control of how often that UI changes), but it can also lead to ToS violations, and credential management headaches.
Most web apps have an API, even if it's not public. Check DevTools network traffic and build a spec from what you find. If there are docs but no registered API, generate a spec from the docs. That's a gap Jentic's docs-to-spec skill is built for.
If there genuinely is no API, I'd recommend engaging the vendor and push for access, especially if you are paying for that service. Browser automation is a temporary workaround, not a strategy. Agents that scrape through a UI can break on every UI change and can't scale.
Structured APIs are the only sustainable path. Anything else is technical debt dressed up as a solution.
@frankkilcommins Allow me to disagree) I believe the future is in agents that act like humans. These are agents that assist in everyday actions. Why can’t I tell an agent: “Write a Twitter post with the text XXX on my behalf”? Or: “Order me XXX light bulbs on Amazon for my chandelier”? This is a very in-demand scenario, and there is no place for APIs in it. And yes, right now this is not a guaranteed outcome — the AI may misunderstand something — but in the future AI will be smarter and in 99% of cases these scenarios will be executed successfully.
Does this violate terms of service? In many services — yes. At the moment, services will have to change this, it seems to me. But: 1. People need this 2. People will perform everyday actions without harming services 3. Such actions are done from browsers, so services will not be able to track them
@natalia_iankovych We're absolutely aligned on the goal: agents that act on your behalf, handling everyday tasks without friction. That's exactly what Jentic Mini opens up. Access to 10,000+ APIs, hundreds of pre-built workflows, and the ability for your agent to mint new workflows on demand.
Where I'd push back is on "there is no place for APIs in it." The scenarios you describe (posting to Twitter, ordering on Amazon) are already powered by APIs. The interface the agent uses (UI, API, CLI, MCP) is a separate question from the outcome. And regardless of which interface you choose, you do not want agents holding raw credentials or keys with unscoped access.
On ToS: banking on services changing their terms to accommodate autonomous UI login is a real assumption. The API route doesn't require that bet.
99% may be possible at some point, but the complexity of the situation will always dictate the actual failure rate. That 1% looks very different when it's your bank account, order history, or health records
The shift happening right now is that APIs, CLIs, and MCP are becoming the preferred interface for agents. Structured, predictable, auditable. The UI becomes secondary, not because UIs are going away, but because agents work better with interfaces designed for machines.
@frankkilcommins Yes, healthcare and finance will be the last to be automated, I agree. And I also agree that APIs are more reliable. If there’s a choice between doing it via an API or as a user, everyone will choose the API. But if the API doesn’t allow it, then there’s only one option. And there are quite a lot of such cases. Just yesterday I read that Amazon banned agents from making purchases through the courts because demand had started shifting there.
Clipboard Canvas v2.0
The ability to avoid hardcoding secrets and dynamically inject creds part is genius, it saves so much headache. What’s been the biggest challenge in curating the API catalog, especially in keeping it updated and reliable?
@trydoff Thanks! The credential injection piece is where most setups fall apart, so glad it resonates.
The catalog challenge is real and multi-layered. The biggest headache? Invalid or incomplete OpenAPI descriptions. A lot of published specs are technically valid but practically unusable: wrong base URLs, missing auth schemes, undocumented parameters. Several of us have been deep in OpenAPI tooling for years, which helps us spot and fix issues fast. Where we need to upgrade or patch specs, we lean on the OAI Overlay spec rather than forking definitions, which keeps the chain clean.
Sourcing is the other piece: finding the canonical definition, tracking it, and knowing when it changes. We've built polling mechanisms for that, but the longer play is working directly with API providers on more integrated sync processes. That's where we're investing now.
For APIs where we only have docs and no reference definition, we use our jentic-api skill to generate the OpenAPI from the documentation. Not perfect, but it gets us 80% of the way there fast.
Community contributions are also helping in keeping coverage broad and current. If anyone here wants to help with a specific API, we'd love the input.