
Launching today

PandaProbe
open source agent engineering platform
475 followers
open source agent engineering platform
475 followers
PandaProbe is an open-source agent engineering platform that gives you deep observability into AI agent applications. Use it to trace, evaluate, monitor and debug your AI agents in development and production.








PandaProbe
👋 Hey Product Hunt!
I’m Sina, founder of PandaProbe.
Building AI agents is getting easier, but understanding and trusting them in production is still hard.
Once agents start calling LLMs, tools, APIs, MCPs, and sub-agents, logs aren’t enough anymore. You need to see what happened, why it failed, whether quality regressed, and how reliable the system is across full sessions.
PandaProbe is my attempt to solve this: an open-source agent engineering platform for tracing, evaluation, monitoring, and debugging AI agent applications.
The goal is simple: help developers move from “it works on my laptop” to “I understand production behavior, can measure quality, and continuously improve it.”
What PandaProbe provides
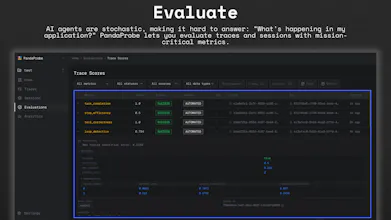
🔎 Trace — capture full agent executions as sessions, traces, and spans across LLMs, tools, agents, and custom logic.
📊 Evaluate — score traces and sessions using mission-critical, agent-specific metrics.
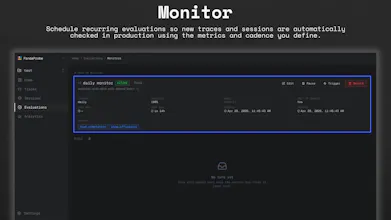
⏱️ Monitor — schedule recurring evaluations to automatically validate new traces and sessions in production.
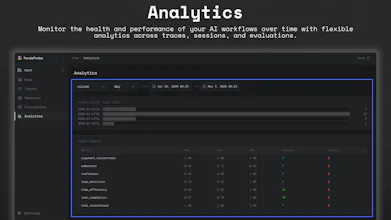
📈 Analytics — track performance, cost, latency, errors, and quality trends over time.
🛠️ Open source + cloud — use the open-source core on GitHub or run PandaProbe in the cloud.
Who it’s for
🧑💻 AI engineers — debug agent behavior across LLMs, tools, and workflows.
🏗️ Platform teams — monitor quality, regressions, and reliability in production.
🔬 Builders experimenting with agents — understand failures and iterate faster.
🚀 Startups — add observability and evaluation before things become unmanageable.reason about.
Quick links
GitHub: https://github.com/chirpz-ai/pandaprobe
Docs: https://docs.pandaprobe.com
Cloud: https://www.pandaprobe.com/
I’ll be here all day answering questions and collecting feedback.
If you’re building agents today, what’s the hardest part to debug or evaluate?
Thanks for checking it out 🙏
— Sina
Okan
Handling state and debugging for long-running autonomous agents is usually a nightmare, so having an open-source platform to standardize that workflow is huge. I can definitely see myself using PandaProbe to self-host my agent evaluation pipeline to keep sensitive client data entirely local. I am really curious to hear if you currently support custom tracing for raw API calls instead of just the standard frameworks.
PandaProbe
@y_taka Really appreciate that — and yes, democratizing observability and enabling teams to keep sensitive workflows fully self-hosted were big motivations behind making PandaProbe open source from day one.
And absolutely: we support custom tracing beyond standard frameworks. Alongside native integrations, PandaProbe also provides manual instrumentation APIs and decorators, so you can trace raw API calls, internal services, custom orchestration layers, or essentially any part of your agent workflow you want visibility into.
A lot of teams end up with hybrid architectures, so supporting low-level custom instrumentation was important for us early on.
Evaluation is the hardest part of this whole space and most platforms hand-wave it. The failure mode that actually bites in production isn't crashes or schema errors. It's slow drift in subjective quality (voice, classification accuracy, output style) that only shows up when a human reads 50 outputs in a row. How does PandaProbe handle that in practice? LLM-as-judge with custom rubrics, human-in-loop on a held-out set, embedding-distance from a golden corpus, or something else? And how do you stop eval cost from outpacing inference cost when you're re-judging every trace?
PandaProbe
@vincentf This is actually one of the core motivations behind PandaProbe.
A lot of evaluation systems today focus on isolated outputs, but in production we kept seeing failures emerge as trajectory-level drift: looping, degraded tool grounding, coordination breakdowns, subtle quality regression, output-style drift, etc. The model can still sound confident locally while the overall session quality quietly collapses.
That led directly to a research paper I recently published called TRACER (Trajectory Risk Aggregation for Critical Episodes in Agentic Reasoning). The core idea is evaluating uncertainty and failure at the trajectory/session level rather than the individual response level.
That research became a major foundation for PandaProbe’s evaluation system and heavily shaped how we think about observability and longitudinal agent evaluation.
On the cost side, we’re also very conscious about evals becoming more expensive than inference. PandaProbe supports async and sampled evaluations, composable metrics, and lightweight structural trajectory signals so teams don’t have to run expensive judge models on every trace.
FuseBase
PandaProbe
@kate_ramakaieva Thanks for the support, Kate! Great question.
If you’re using one of our supported integrations for frameworks like LangGraph, CrewAI, and others, MCP tool calls are automatically captured and traced out of the box.
For custom agent architectures or internal tooling, we also provide lightweight manual instrumentation via decorators, so you can trace virtually any function, tool call, or workflow step in your agent logic.
Really nice work. The gap between "it ran" and "I understand what happened" is enormous for agents and nobody's solved it cleanly yet. Rooting for you!
PandaProbe
@igorsorokinua Really appreciate that and I completely agree. That gap becomes painfully obvious once agents start interacting with tools, memory, APIs, and other agents in production.
A big part of PandaProbe’s vision is making agent behavior actually inspectable (like traditional software engineering) and understandable instead of feeling like a black box.
MyLens AI
Great pain to tackle, Sina. Good luck.
PandaProbe
mcp-use
Congrats on the launch and thanks for using mcp-use :)
PandaProbe
@pederzh thanks for the support Luigi. I'm a big fan of mcp-use :)