

ReCognition
Stop RAG Hallucinations with Table-Aware Document OCR
2 followers
Stop RAG Hallucinations with Table-Aware Document OCR
2 followers
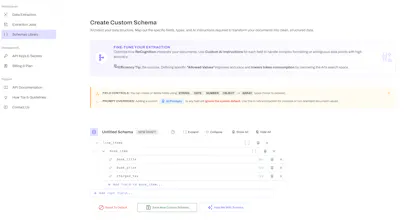
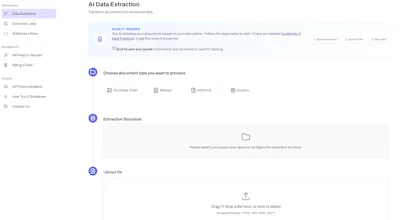
Stop RAG hallucinations at the ingestion layer. ReCognition converts messy PDFs, complex tables, and handwriting into high-fidelity, LLM-ready JSON. Define dynamic extraction schemas to match your Vector DB's metadata needs, or use our pre-trained models. Built for production-grade engineering: stateless processing guarantees zero data retention. Deploy our OCR engine on-premise or in your own VPC to maintain absolute control over your pipeline.

Hey builders! Is poor context extraction causing hallucinations in your RAG app?
We built ReCognition to fix the RAG ingestion layer. Stop wrestling with generic PDF parsers that break tables and lose hierarchy. We provide a prompt-driven API where you define the extraction schema, and we deliver structured, semantic JSON - no matter how messy the source document is.
EU-hosted, stateless architecture (no data retention), with an on-premise deployment option.
Free in open beta, with 50% off for life for Product Hunt users.
Would love your feedback. What's the "toughest" document in your pipeline right now that standard loaders can't handle?