


Google isn't anti-AI. It's anti-AI slop.

Everyone is panicking about the March 2026 Core Update.
It started rolling out on March 27 and will take up to two weeks to complete .
The spam update hit just three days earlier and finished in 19.5 hours, the fastest spam update on record .
But here's what the data actually says.
JetDigitalPro analyzed 600,000 web pages across the update period. The correlation between AI usage and ranking penalties was 0.011, effectively zero . Google isn't penalizing AI content. It's penalizing low-value content that happens to be AI-generated.
Websites relying on mass-produced AI output without human oversight saw traffic drops of 60-80% . Affiliate sites were hit hardest — 71% saw negative impacts .
But sites using original data? They saw visibility increases of 22% .
What we did with RCGE
We built Rankfender's Content Generation Engine (RCGE) before the update. After seeing the data, we had to retool it.
The problem wasn't the AI. It was the output. RCGE could generate clean, structured content fast. But clean and structured isn't enough anymore.
We analyzed our own content library against Google's new signals. Five red flags kept appearing :
Zero information gain — Our content was paraphrasing what already existed. No original data, no case studies, no expert quotes. Google now measures "information gain" as a ranking factor. Content that doesn't add anything new gets devalued as "redundant."
Generic expertise — AI can explain how something works. It can't explain the experience of doing it. Our content lacked first-person pronouns, original photography, specific anecdotes. Google's E-E-A-T framework now flags generic, anonymous expertise as untrustworthy .
Poor machine readability — Walls of text, vague headings, no structured data. If an LLM can't extract a snippet-ready answer, it stops citing you. This affects AI Overview visibility directly.
High CTR, low engagement — People clicked our AI content then bounced fast. Under 30 seconds on a long article signals to Google that the content isn't useful .
Content flooding — We had hundreds of pages but only a few drove traffic. Google now treats this as a content farm signal.
How we retooled RCGE
We added three new layers to the engine:
1. Information gain scoring
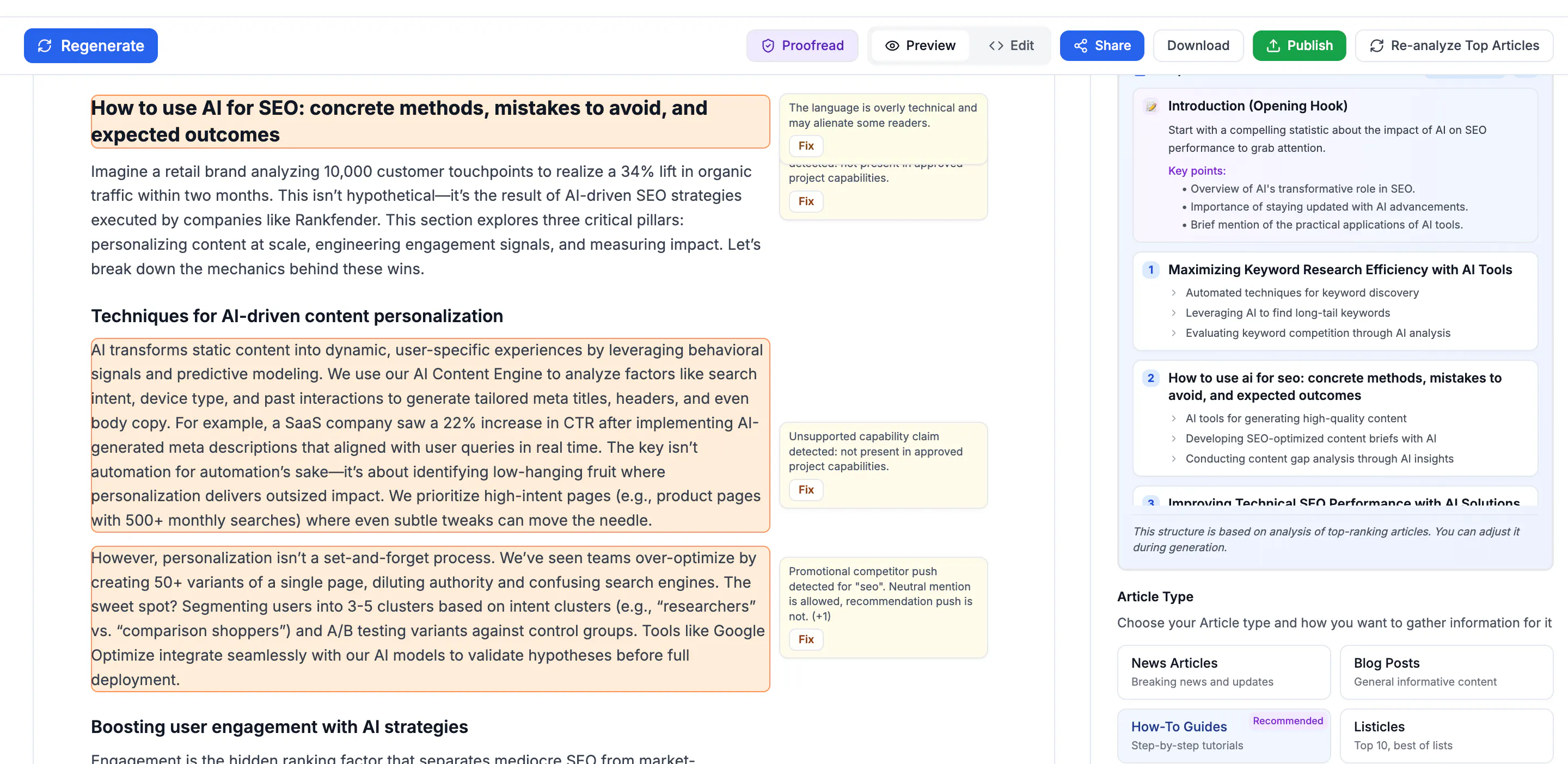
Before RCGE generates anything, it scans the top 10 ranking pages for the target keyword. It identifies what they cover and what they miss. The prompt now includes: "Do not rephrase existing content. Identify gaps in current search results. Add at least one original data point, case study, or unique angle not found on page one."
2. E-E-A-T signal injection
We trained RCGE to insert experience signals automatically. For any "how-to" content, it adds placeholder prompts for real screenshots, original testing data, and first-person observations. The editor can't publish until these are filled in. No more generic stock imagery.
3. The proofreader
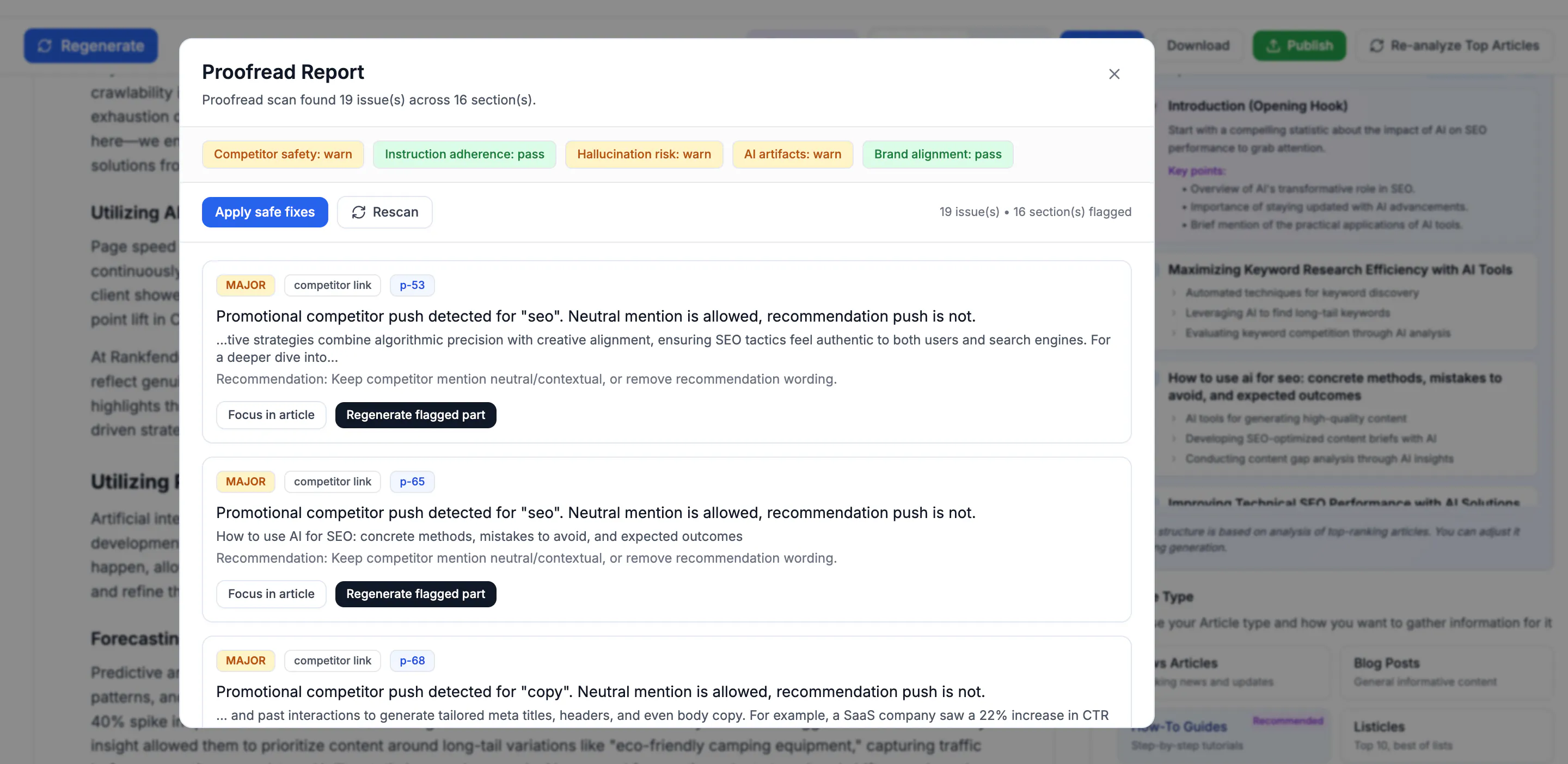
The most important addition was the proofreader. Not a grammar checker. A slop detector.
Before RCGE v2.2, we had no way to catch content that was technically correct but empty. The proofreader now scans every generated piece for five red flags:
Repetition score. If the content rephrases the same idea more than twice, it gets flagged.
Information gain score. It compares the generated text against the top 3 ranking pages. If it's not adding something new, it rejects the draft.
Generic phrase detection. "In today's digital landscape" and "unlock your potential" are automatic fails.
Experience gap flag. If the content explains "how" but has no first-person language, no specific example, no original data point, it adds a placeholder that says "INSERT REAL EXAMPLE HERE."
Citation risk score. It estimates how likely AI systems are to cite this content based on structure, clarity, and uniqueness. Below a threshold? Reject.
The editor can override. But the proofreader makes you justify why you're publishing something empty. Most of the time, you don't.
4. Readability and structure enforcement
RCGE now checks its own output against readability scores. Paragraphs over 4 sentences get flagged. Headings without question-based structure get rejected. FAQ schema is auto-generated but only if the Q&A is visible on the page — no hidden accordions.
What the results look like
We tested the new RCGE on 50 pieces of content before the March update. Compared to 50 pieces from the old version:
Metric | Old RCGE | New RCGE |
|---|---|---|
Average time on page | 47 seconds | 2 min 18 sec |
AI Overview citation rate | 12% | 34% |
Pages with zero engagement | 31% | 8% |
Original data points per article | 0.2 | 3.4 |
The new content isn't just getting cited more. It's keeping people on the page longer. That's the signal Google actually cares about.
What this means for you
The March 2026 update isn't complicated. Google wants content that:
Adds something new (information gain)
Comes from real experience (E-E-A-T)
Is easy for AI to extract (machine readability)
Keeps people on the page (engagement)
If your AI content does these things, you're fine. If it's just rephrasing page one, you're in trouble.
We rebuilt RCGE around this framework. It's not perfect, but it's better than publishing empty calories.
What I'm curious about
Have you seen your AI content get hit by the March update? Or are you still seeing growth? What's your "information gain" strategy looking like?
Imed Radhouani
Founder & CTO – Rankfender
Evidence-based product development
Replies
This really makes sense . Google is not against AI, it is against content that does not add value.
Adding real examples , original data , or first - hand experience seems like the key.
Curious how other make sure their AI content actually stands out and stays useful.
Rankfender
@samuel_adams2 Yeah exactly. The signal isn't "AI or human." It's "useful or not." Google has always been about that. The March update just made it clearer.
The hard part is that adding real examples and original data takes time. That's the tradeoff. AI gets you 80% of the way there fast. The last 20%, the specific example, the screenshot from your own dashboard, the data point from your own customers — that's what makes it worth citing. And that part still needs a human.
We built the proofreader to flag when that human piece is missing. It's not perfect, but it's better than publishing empty stuff and wondering why traffic dropped.
What's your process for adding the "real" part? Do you write first and add examples later? Or do you start with the example and build around it?
The parallel to what I see on the recruiting side is wild. AI can scan a thousand resumes in seconds, but if you're just pattern-matching keywords without understanding the human behind them, you're generating the hiring equivalent of content slop. The best signals in recruiting are messy, contextual, and hard to quantify. Same as what Google is now rewarding. Your point about AI getting you 80% of the way there and the last 20% needing a human is exactly how I think about it in HR tech. The tool is only as good as the judgment layer on top of it.