

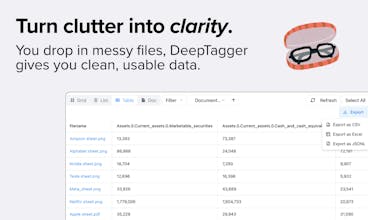
DeepTagger is a no-code platform that makes your judgment scalable. It uses your annotations as an example to extract information from new documents. Highlight what matters to you once, and let DeepTagger handle the rest with precision. API access included.














DeepTagger
This product was born out of real-life problems 📨
While analyzing the Enron Email dataset for a PhD project, we needed to extract data from hundreds of thousands of emails in various formats, and then trace chains that included incidents of “knowledge hiding.”
But we got stuck on the very first task: splitting long email chains into individual emails.
Custom Python parsers failed.
RegEx broke.
Traditional ML tools, such as spaCy Prodigy, or Label Studio, couldn’t handle the complexity 🤯
Doing it manually would have meant admitting defeat.
So we built our own annotation tool that could handle nested data structures 🛠️. However, even with perfect annotations, traditional models couldn’t generalize — the data was too diverse, and the examples were too few.
Then OpenAI posted "Introducing Structured Outputs in the API," and everything clicked ⚡
Our annotations became few-shot examples instead of training data.
✅ No model training needed — just smart prompting.
That’s when we realized this could compete with traditional OCR tools by offering a completely different experience.
A few months of polish later… Deeptagger was born 🚀
Hope you love it! ❤️
@talshyn sounds very interesting! We should try it 👍🏻good luck!
DeepTagger
@aknur_zh thank you so much, Aknur! 🙌 Your feedback would be super valuable 🥰
Scade.pro
@talshyn congrats on the launch! if the file is quite old, like a pdf of a scanned XIX century book, can it extract text from it, or it only works after ocr?
DeepTagger
@talshyn @nastassia_k Great question! DeepTagger has built-in OCR, so it can absolutely handle that XIX century scanned book, no additional tools needed. When comparing this product to OCR-based extraction tools, I meant that we aren't defining what needs to be extracted in terms of bounding boxes. We use full-page OCR as step one, but DeepTagger's real power comes from everything that happens next. You get from scanned pixels to structured, actionable data in one seamless process.
Scade.pro
@talshyn @avloss awesome, thanks!
@talshyn congrats, looks nice!
do you have a teamspace, can I collaborate with my teammates on my dataset?
DeepTagger
@talshyn @olga_scry This is an amazing idea, we should definitely try to introduce it in the next version of DeepTagger!
DeepTagger
@olga_scry thank you for bringing this idea 😍 How would you ideally see your teammates working together inside DeepTagger?
A very amazing product! I’m sure this will put it to good use in research and reading! We always want to be able to quickly get the key points of a document and see how tags are associated with the documents. DeepTagger will solve this problem very well.
I like the idea and its implementation. I will follow the development of the project!
Good luck!
DeepTagger
@serg_krasakovich thank you so much, Siarhei! 🙏 Really glad you like it, we’re excited to keep improving Deeptagger and appreciate your support!
DeepTagger
@serg_krasakovich Thank you for checking us out! We'll regularly update on our progress!
Agnes AI
It is tediuous to deal with new docs..... I really hope DeepTagger could offer a hassle free solution for data users like us!
DeepTagger
@cruise_chen Thanks for checking us out! Absolutely you can offload working with those docs in inconsistent formats to us, anything that has text on it we can pretty-much process! Since Deeptagger is extremely flexible, we can extract format like "paragraph name / paragraph content" (if content of docs varies too much) or any other format that suits you. We can show you a quick demo if you have moment! We can integrate via API, or, even MCP, although it's still in alpha not fully released on our part.
DeepTagger
@cruise_chen absolutely 🙌 Can’t wait to see it in action for your workflow!
DeepTagger
@tima_sulaimon Right now we have API integration released, but we have MCP in the works, so, in the future, you should be able to plug both your Google Drive and DeepTagger into your favourite LLM Client, like Claude Desktop, then you'll be able to issue instructions like "Select key information from contracts in the folder A, do three documents", it'll do this for you, then you will review how it extracted that information, ensure that this is indeed the information that you want, make amendments right on the documents and then tell LLM "Now please continue and select key information from the rest of contracts in the folder A", save it into a Spreadsheet. So, while other steps are already possible, what DeepTagger introduces here, is the ability to inspect and amend the information that's being extracted, so it'll be doing precisely what you need!
Migroot
Congrats on the launch @talshyn Really impressive work!
How do you see it competing with traditional OCR and annotation tools?
DeepTagger
@talshyn @kate_prasniak We try to take best of both worlds, free text annotation like in a traditional annotation tool, but with support for complex nested objects and well defined schema. DeepTagger can absolutely do POS or NER tagging, but it'll be an overkill to use DeepTagger for that. There's also OCR-like functionality, we work with PDFs, images, DOCX. Additionally, this works somewhat similar to how train sets are prepared with traditional annotation tools, except we only need a few examples. So, this is more of a universal data extractor tool.
Looks super handy for pulling structured data from docs. Highlight, tag, and no-code flow feels clean and intuitive. Congrats on the launch!
DeepTagger
@iamrajanrk thank youuu! 😊 We designed @DeepTagger to keep things simple but powerful so that you can focus on the data, not the process. Excited you like it!
DeepTagger
@iamrajanrk Thank You Rajan! We'll keep trying!