

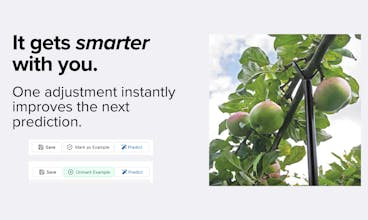
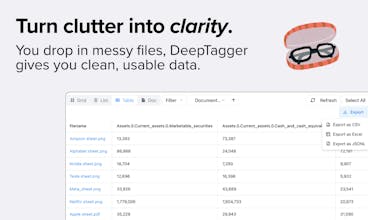
DeepTagger is a no-code platform that makes your judgment scalable. It uses your annotations as an example to extract information from new documents. Highlight what matters to you once, and let DeepTagger handle the rest with precision. API access included.













Integrity
Good job! Splitting messy email chains is such an underrated nightmare. Amazing to see you tackle it head-on with structured outputs.
DeepTagger
@alesia_cherniavskaia Thank you, yes indeed! 😅
DeepTagger
@alesia_cherniavskaia really glad this part resonated with you! Thanks a lot for the support 🙌
@talshyn Very exciting product, does the ocr engine parse any annual reports/ and investor decks available online?
DeepTagger
@talshyn @shashwat_ghosh_gtm Thank you Shashwat, great question. We're working on ingestion of documents via links, but this is not present in the current version. So, if the document is public, then it should be possible to ingest it in the future versions.
Incredible
Love this tool and the concept! Really curious to know whether you guys will have an API real soon? 👀
DeepTagger
@yesith_thomas_official We already have fully working API integration, and it's already fully live and processing real documents in production settings! You can try it today, there is a tutorial on our website. Next step for us would be MCP and other integrations.
DeepTagger seems like an ideal tool for teams who need to turn messy, unstructured documents into usable data without spending weeks. Are there any export options / downstream integrations as well to push the extracted data into a database or analytics tool ?
DeepTagger
@lakshaygulati Thank you for checking us out! Currently we support manual export into Excel/CSV/JSONL, as well as API integration. MCP is in alpha and not public yet, also, we're planning to keep adding additional integrations continuously.
Coming from the perspectives of the university students and of any person handling with tons of documents, this platform will be really helpful to categorize and extract needed information!
DeepTagger
@salome_khurtsidze thank you so much, Salome! 🙏 We’re happy to hear this 🥰Deeptagger aims to make handling large volumes of documents much easier, so categorizing and extracting key information becomes fast and intuitive. Excited to see how it works for you! 🚀
DeepTagger
@salome_khurtsidze Thank you for checking this out! It absolutely can be used for pure categorisation too, but it shines the most when extraction is also need.
Wow! I like it! Congrats on the launch!
What are the pricing options?(no info on pricing page)
DeepTagger
@michael_vavilov Thank you! 😄 Right now we have pay-as-you-go token based pricing. But we also have Enterprise plan, where we can negotiate a specific price. It's free to start, and there should be enough allowance to get real feel for how our platform works.
Scrumball
The Enron dataset pivot story is wild!
PhD projects always seem to turn into building the tools you wish existed.
I totally feel the pain of custom parsers failing on messy data. We process millions of social media posts for influencer analysis and the format inconsistencies are a nightmare. RegEx works until it spectacularly doesn't.
Quick question though - how does it handle really domain-specific annotation tasks? Like if I need to extract sentiment and engagement metrics from Instagram comments in different languages, can it adapt to those custom categories pretty easily?
DeepTagger
@alex_chu821 It handles any domain-specific annotation tasks if the information is there to begin with. We tried it on everything from Court Decisions in Estonian, to amateur poems, to patents, to text generated with LLM itself. It can adapt to any categories, any domain. It's as good as latest LLM powering it.
So It won't be able to predict "winning lottery numbers", regardless how many example you provide it. But if it's something that's "doable" in principle, then it absolutely can do it - across languages, across formats, across domains, across tasks. For instance if you want to teach it something really basic like POS, or NER - it might take 1 or even 0 examples. For Court Decisions - it might take 2-3, depending what you're trying to get out. You can provide examples in one language and format, and it'll be able to extract in completely different format and any language. You can provide examples in PDF for instance and it'll extract from Markdown, or PNG files.
An early thing we've tried was amateur poetry, we had an expert judge, who often judged those poetry competitions, who would annotate amateur poems for things like "clichés" or "metaphors". I was sitting there and I couldn't even tell if something is a cliché or not. Even person who was annotating had doubts at times. This was extremely hard task, since there's no "ground truth" in principle. In this case it took around 4 hours and 40 examples, until models annotations started to match what expert was providing.
For any domain where the truth is "more-or-less" objective - only few examples would be sufficient. And if we're extracting something subjective, more examples might be needed, but still, it will always converge, if it's possible to converge.
Scrumball
@avloss The cross-language and cross-format adaptability is impressive - especially the ability to train on PDFs but extract from completely different formats like Markdown or images.
The amateur poetry cliché detection example is fascinating because it shows the system can learn subjective judgment calls, not just objective data extraction. 40 examples to match expert-level annotation on something that subjective is pretty efficient.
For our use case with social media sentiment analysis, we often deal with slang, cultural references, and context that changes rapidly. How does it handle situations where the "ground truth" might be shifting over time - like when internet slang evolves or cultural sentiment around topics changes?
DeepTagger
@alex_chu821 This is sort of a problem DeepTagger can handle well, as long as you have a domain expert onboard. For evolving contexts like slang and cultural sentiment, you can continuously improve "model" with fresh examples as language shifts (or updating old examples). Since it only needs a few examples to adapt, you could update your models monthly/quarterly with current slang samples.
Happy to show you how this works with some real social media examples if you're curious!
Scrumball
@avloss The continuous update approach with domain experts makes sense for handling evolving language. Monthly or quarterly refresh cycles could work well for staying current with slang trends.
I'd be interested in seeing those real social media examples. Social media sentiment analysis is tricky because context shifts so quickly - what's positive language today might be sarcastic tomorrow.
The key challenge we face is maintaining annotation consistency when the same phrase can have completely different meanings depending on platform culture or even specific communities within platforms.