Hey, I'm Sacha, co-founder at @Edgee
Over the last few months, we've been working on a problem we kept seeing in production AI systems:
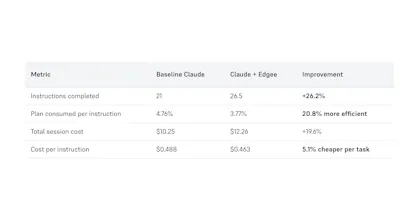
LLM costs don't scale linearly with usage, they scale with context.
As teams add RAG, tool calls, long chat histories, memory, and guardrails, prompts become huge and token spend quickly becomes the main bottleneck.
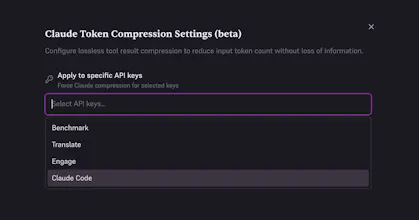
So we built a token compression layer designed to run before inference.








 Portkey Prompt Engineering Studio
Portkey Prompt Engineering Studio