

Grok Voice Think Fast 1.0
Our most capable voice agent is now available via API
130 followers
Our most capable voice agent is now available via API
130 followers
A state-of-the-art voice model built for complex, multi-step workflows with snappy responses and high accuracy.
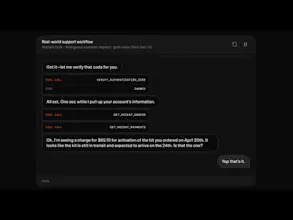

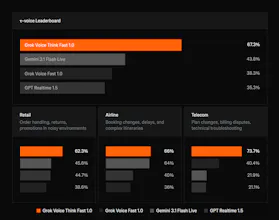
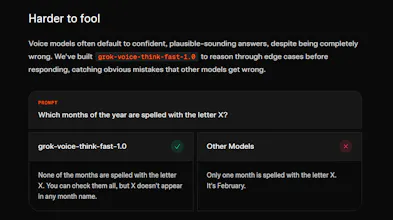

Voice quality and latency in AI agents is one of those things that's invisible when it works and immediately kills engagement when it doesn't. The "snappy responses" point resonates — for any use case where the conversation has to feel natural (customer support, voice-driven workflows, interactive media), hesitation breaks the illusion.
I've been thinking about this in the context of audio content more broadly. I run a podcast on financial modelling called ModeLoop (https://open.spotify.com/show/0m1oR8AyQv17DVpc5MmirG) and the question of how voice AI changes long-form audio is interesting — not just production quality but whether models like this eventually enable interactive podcast-style experiences where listeners can ask follow-up questions.
For the API use case, what's the typical latency for a first-token response in a complex multi-step workflow scenario?
snappy + multi-step is the hard combo to nail at the same time — most voice models trade one for the other. what's the latency look like end-to-end on a typical multi-turn workflow?