

intura
Compare, Choose, and Save on AI
152 followers
Compare, Choose, and Save on AI
152 followers
A platform that helps businesses compare, test, and optimize AI models, making it easier to select the best-performing and most cost-effective AI for their needs.





intura
Hey fellow builders! I’m @najwa_assilmi, and together with my co-founder @ramadnsyh , we’re building @intura🐰 —a platform to help you experiment, compare, and monitor LLMs with ease.
Everyone’s building LLMs. Few are testing them like they mean it. We believe the real edge comes after the build—when you’re benchmarking, refining, and shipping with confidence.
We like our tools fun, witty and functional. Inspired by Theseus—the maze-solving mechanical mouse🐭 built by Claude Shannon in 1950—we chose a rabbit as our symbol. For us, it represents the curious, twisty journey of finding the best model setup for your users.
We’re currently in beta and would love your feedback. 🐇💌
Try it out—and let us know what you think. We're all ears!
With ❤️,
Intura
Hey! Are you using a documentation only (e.g. compare prices, prompts, etc.) or a real tests with AI API's?
intura
@kirill_a_belov Hi, thank you for your question! We’re running real tests using live AI APIs like OpenAI and DeepSeek to compare models directly. When we hit the API, we collect data such as response time, input, output, and token usage, then use that to analyze and compare performance across models.
In the current beta, we’re actively building out the live experimentation flow—so more is coming soon!
intura
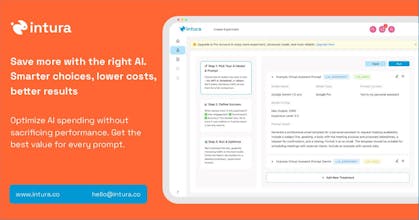
As LLM developers, we know the pain of constant iteration and production challenges 😩. Every model and prompt change feels like a new rabbit hole 🐇. That's why we built this platform – to streamline LLM production experimentation 🚀. We empower engineers, product teams, and businesses to collaborate effectively, track experiments, and optimize AI ROI.
Key Features:
Version Control: Track prompt changes and model versions 🔄.
A/B Testing: Compare different LLM configurations in real-time 🔬.
Collaborative Workspaces: Enable seamless teamwork between technical and non-technical users 🧑💻🤝🧑💼.
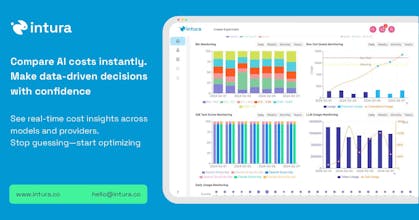
Performance Monitoring: Gain insights into LLM behavior and user interactions 📈.
Data-Driven Optimization: Make informed decisions to improve AI performance and ROI 💡.
How To Use Our Platform:
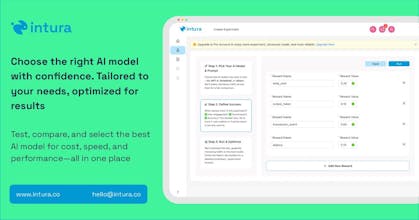
Create Your Experiment and Variations:
Start by defining your core experiment. For example, testing different LLM models for a specific task 🎯.
Create variations within your experiment by comparing models like DeepSeek, ChatGPT, Claude, and Gemini 🤖. You can also vary prompts within each model.
Set Your Optimization Goals:
Define clear optimization goals to guide your experiment. Are you prioritizing performance, cost, or a balance of both? 🤔
Quantify your goals with specific metrics. For instance:
Token usage: Aim for a 30% reduction 📉.
Transaction success rate: Target a 60% increase 📈.
Latency: Seek a 10% decrease ⏱️.
Run Your Experiment and Monitor in Real-Time:
Launch your experiment and observe the results in real-time 📊👀.
Our platform provides detailed performance monitoring, allowing you to track your defined metrics as the experiment progresses 💻.
Utilize the real time monitoring to make adjustments as needed.🔧
We believe LLM experimentation shouldn't be a daily struggle 💪. Let us know what you think! 🎉
This seems like a good evolving opportunity for cost monitoring. Excited to see where this goes!
Congrats on the launch! This looks really useful. I’m curious, does it also support comparing expected vs actual outputs? For example, if I expect a "yes" or "no" answer, can I define that and see how each model performs against it? Would love to try it out!
intura
@fragtex_eth Thanks for the kind words and great question! As part of our upcoming roadmap for robust evaluation, we're adding online and offline methods, including label provision. For example, with offline methods, you'll be able to compare expected vs. actual outputs, like your 'yes/no' example, to assess model performance. We use backtesting and sandbox simulations before live experiments to minimize cold starts and maximize ROI. We're happy to discuss this further and show you how it works!
For anyone building AI products, having metrics around performance and cost in one dashboard could dramatically simplify the decision-making process. Curious to see how the expected vs. actual output comparison develops in their roadmap - that's a must-have for serious evaluation.
Congratz on the launching btw.
intura
@tomcao2012 That’s great feedback.. thank you! Totally agree: Making expected vs. actual output comparison smoother and more insightful is high on our roadmap and we’re excited to share more on that soon!
This tool makes model evaluation seamless! 👍
intura
@shenjun Huge thanks! We're open for any feedback 🐰