
Launching today

Jitera
Shared context that turns AI into your teammate
63 followers
Shared context that turns AI into your teammate
63 followers
Jitera gives your team a shared context graph — so AI agents stop guessing and start working like real teammates. Trusted by Panasonic, Asahi Life, Sumitomo Electric, and 100+ teams.



Jitera
Hey PH 👋 I'm Yota, one of the makers of Jitera.
Turn AI into your teammate. With shared context.
Over the past year, AI went from novelty to daily tool. But something still feels off.
Everyone prompts their own AI in their own tab. Outputs get copy-pasted, nobody reads them, and the team falls out of sync. Your organization isn't learning, it's just generating.
Even with AI everywhere, teamwork itself hasn't changed.
Here's what we believe: without context, AI is a genius goldfish, brilliant in the moment, then forgets everything. With shared context, it becomes your teammate.
Jitera builds that shared context as a Context Graph — connecting your code, docs, decisions, and tribal knowledge so every agent knows who owns what, what was decided, and what's already been tried.
That's Jitera.
What it looks like 👇
🧭 Context Graph
Connect docs, data, decisions, and people into shared context your agents can actually use.
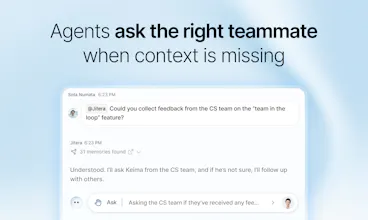
🌱 Agents that grow your context
Agents ask the right teammate when context is missing — so your shared context keeps getting sharper.
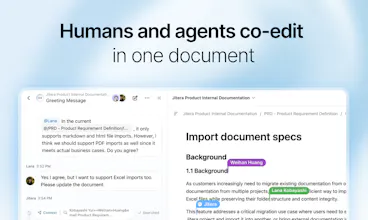
📝 Humans and agents co-edit
Docs, specs, and notes edited together by humans and AI, in the same document.
💬 One shared thread, not 100 private tabs
The whole team chats with agents in one place. No more copy-paste from private ChatGPT windows.
Not just faster outputs. Better decisions, made together.
We're early, and we're building this with teams who want AI that actually fits how they work. If that's you, we'd love your feedback — the sharp kind 🙏
👉 https://jitera.com/
— Yota & the Jitera team
Hey, Ivan here, I work on Jitera.
Before this I spent a few years building open-source tooling for people running their own LLMs and agent stacks, so I came into the project with strong opinions about what agent platforms tend to get wrong.
I want to talk about the part of Jitera I'm very proud of, which isn't really something you'd put on a marketing page. It's how the platform is built underneath.
The obvious way to build something like this is to make one big core that handles everything itself. The platform decides how memory works, where telemetry goes, what file storage looks like, which LLM runtime gets used. That demos great, but breaks down when someone asks if their agents can route usage data to their own observability stack instead of ours, and another wants their agents to mount an S3 bucket as if it were a local filesystem, and a third wants to swap the LLM runtime to Anthropic's Claude SDK for one specific team's agents but not the rest. In the all-in-one version, each of those becomes its own fork in the codebase, and a year later it transforms into something nobody can reason about.
We built it differently, so every behavior in the platform is a small piece of middleware wrapped around the agent loop. Memory, telemetry, input classification, the cloud bucket mounts, even the LLM runtime itself, they all have the same shape and they stack on top of each other without interfering. Adding "always preload this URL into the agent's context" is just a tiny self-contained module, and the bucket mount and the per-agent telemetry sink are around the same. New behaviors plug in without making the platform more complicated. One interesting bit is that Jitera's own agents are built on the same exact primitives, so anyone using our products can replicate or enhance our agents on their own.
I've worked on enough infrastructure to know this is the kind of decision that pays you back every time and really proud of everything this direction enabled us to do.
I really hope that you'll like the product's flexibility and features, excited to see how it'll be used :)