

Pioneer
Fine-tune any LLM in minutes, with one prompt
203 followers
Fine-tune any LLM in minutes, with one prompt
203 followers
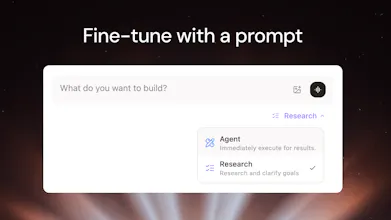
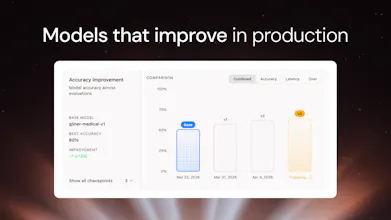
Fine-tune SLMs in minutes. Describe your task in plain English and our agent handles everything: data generation, training, evals, and deployment. Models deployed on Pioneer also keep improving automatically from live inference data. With Pioneer, anyone who can write a prompt can now build production-grade AI that gets smarter over time.






Pioneer
Viseal
hi @ash_lewis_codes , love the concept of Pioneer and can resonate with the high threshold of SLM fine tuning. Do I understand correctly that the prompt-based fine tuning and continuous fine-tuning refinement through inference can only be supported via cloud hosted models via Pioneer? Is there solution for self-hosted or local inference? thanks and congrats!
Pioneer
Hey @hwellmake Right now fine-tuning is only on our platform. However, Pro subscribers are able to download their own models weights to run everything locally!
@ash_lewis_codes hi!
the synthetic data step is where I'd expect most failure modes to hide.
if the model generating training data shares the same blind spots as the base model you are fine-tuning, you are reinforcing existing weaknesses instead of patching them.
how does Pioneer handle that? is there a diversity check on the generated dataset? or some way to detect when synthetic coverage is too narrow before trainning starts?
Pioneer
@cremer Pioneer doesn’t just dump live inference data back into training and hope for the best. It’s built to be conservative: it curates the data first, adds hard negative examples so the model learns when not to predict something, keeps a held-out confirmation set that never gets trained on, compares multiple training runs instead of trusting one lucky result, and runs regression checks before accepting any new model. On top of that, it calibrates confidence based on real historical accuracy, rolls back changes if performance gets worse, and carries forward examples from earlier checkpoints so it doesn’t forget what it already learned. So the system is designed to get smarter over time without just memorizing recent inference patterns or drifting into overfitting.
@ash_lewis_codes This is really interesting, especially the idea of models improving continuously from real world usage rather than static training.
We are seeing a similar challenge from a completely different angle with Global Sponsor Hub (focused on international hiring), where matching candidates to visa sponsored roles is still surprisingly inefficient and relies heavily on repetition and guesswork.
The idea of systems improving from real interactions rather than predefined rules feels like a much more scalable approach.
Pioneer
Thanks @jennifergriffiths. Love that parallel! Visa sponsorship matching sounds like a perfect example of a problem where learning from real interactions wins.
nice! since all of this data lives on Pioneers end, what about who gets to keep and use the data? will the prompt data be used by Pioneer for further training the models internally?
Pioneer
@itskishankumar Hey! You can download your data and take it off the platform. We're using agent chats to improve the agent but we'll never use training data that you upload to Pioneer in any other customer's models or to train new models for ourselves.
@ash_lewis_codes oh ok! it'll be interesting to see what customers would be willing to let their company data leave their system. i'm guessing you guys have SOC2 and other compliance implementations in your roadmap ahead too! All the best Ash!