
Launched this week

Lenz
Fact-check any statement with source-backed, multi-model AI
28 followers
Fact-check any statement with source-backed, multi-model AI
28 followers
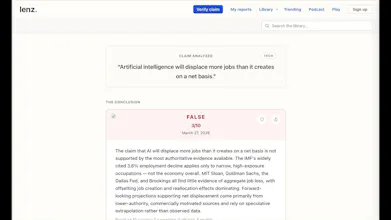
Lenz is an AI fact-checker. Paste any claim and Lenz searches for independent sources, has multiple AI models argue both sides and a separate AI panel review the evidence before reaching a scored verdict — with every source and argument and step of the process visible to you. Most AI tools give you one model's best guess from memory. Lenz orchestrates a multi-model research system based on real sources so no single model's blind spots drive the conclusion. Try it free at lenz.io/ph











Happy launching. I have a question. How do you quantify and mitigate correlated bias across your ‘independent’ AI models and sources especially when those models are trained on overlapping datasets and the sources themselves may share upstream information pipelines so that your multi-model consensus doesn’t simply reinforce systemic errors rather than reduce them?
@bogomep Deep question. Overall concept is to pick the highest-quality available sources/evidence and work with that data (plus the LLM background knowledge which is explicitly listed as a separate source in the output). From that perspective, we don't eliminate correlated bias in the sources, but we try to identify diverse sources and have rules such as looking for sources that support both sides of the argument, and looking for local/regional sources -- that's why if you check, for example, for China, you will get Chinese sources alongside the Western ones. Each source is graded for authority, recency, etc. Retracted research papers are excluded, etc.
With respect to the models, there are two key intermediate steps: (1) adversarial debate between two different models that's aimed to crystalize the positions and arguments and is also valuable for the user to see the strongest opposing arguments, and (2) panel of three different AI models reviews the evidence and the debates in parallel and each model evaluates different axis to detect logical fallacies, biases, context issues, etc. Each of the three panel model is instructed to analyze the data from a different perspective. Then a voting makes the final call, and the executive summary is written. This does not solve correlated bias from shared training data entirely, but helps. And this orchestrated multi-model multi-axis AI pipeline of frontier models has a higher likelihood of producing higher quality output than a single frontier model alone.
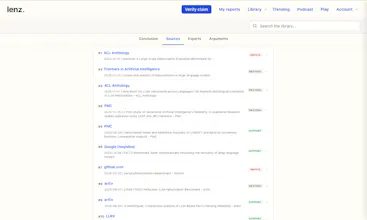
All sources, citations, debates, panel reviews, and voting scores are available to the user to inspect.
I tried lenz with several claims and I liked the way it actually felt like the tool was looking for the most reliable sources out there to confirm with the biggest possible authority if my claims were true or not.
In both situations, the comeback from the tool was great, however I dont know if i loved the ui, here are my points.
The final delivery makes you feel like you are not using the whole screen, there is soo much blank space, it becomes an infinite scrolling of truth, while you could take the full screen and make the information provided more digestible.
Puttingin one side of the screen an index to know what to expect from the full page would be useful, as well as grouping the expert reviews and arguments so you dont have to see them all before passing to the next phase.
Overall i think the tool is great, im excited to know how it will evolve.
PS. I have a product series on my linkedin called "Products that just make sense" I would love to feature Lenz!
@carolinahunts Wow, thank you for taking the time to try Lenz so thoroughly and glad to hear that the core experience of the product resonated.
On the UI comments, we hear you and your feedback is super valuable. Yes, we’ve heavily leaned into transparency - showing the full reasoning, etc, which led to what you called “the infinite scroll of truth” (spot-on!) We are still working on making that process easier to navigate and digest. We really appreciate the deep dive!
Would love to stay in touch as we evolve this. What’s the best way to connect? I couldn’t find your linkedin on your PH profile.
Thanks again
@vicky_dodeva Sure, my linkedin is https://www.linkedin.com/in/carolinatrujillom/
happy to help!
If multiple models are arguing both sides, how do you ensure the final verdict isn’t just "averaging opinions" but actually getting closer to truth?
@lak7 After the debates, we run another step at which 3 other models in parallel review on three different axis the sources/evidence and the debates, and make the final decision. They flag things like biases, logical fallacies, etc. in the arguments (also shown in the final report), and are pretty good at detecting the weak ones.
Amazing! When do we get SKILL + CLI or an MCP so our agents can do fact checking for us? Or a chrome extension
@milko_slavov There's an API available -- https://lenz.io/api/v1/docs/ API keys are managed from the Account menu. Drop me a note if you need any support. There's also a bookmarklet (https://lenz.io/install when accessed from desktop) as a first step before the chrome extension.
@kostaj Great! Here is the skill + cli: https://github.com/mslavov/lenz-cli
@milko_slavov Wow! Amazing! Welcome to the Lenz team :) I will play with the skill & cli later today.
Congratulations!
Does it rely on a single or multi- model approach to perform the fact checking? Any plans for specialized / domain-focused checks - for example solving historic mysteries?
@stefan_lilov Lenz relies on a pipeline that includes several steps. At the key steps (debates and panel reviews), several different forefront models from different providers are run in parallel. We push the models to not rely on their internal factual knowledge, but to focus on evaluating the selected high-quality sources/evidence instead. From that perspective, we don't use domain-trained/focused models in the pipeline, but it's a strong idea to introduce the knowledge of such models at the source level. We already include LLMs internal knowledge as one of the sources (and it's highlighted for the user), but it's not currently coming from a domain-focused model.
When a user start chatting with Lenz (the follow-up questions), then we use a domain-trained model, that also has full access to the source/evidence materials and is restricted to not discuss topics outside of it's narrow domain.
Curious how Lenz handles claims that keep evolving - like the debate around AI code quality. I keep seeing conflicting takes: some say AI writes cleaner code, others say it introduces more bugs.
@vichod Specifically about subjects evolving over time: One of the things we identify during the first step of the process (claim framing) is the time-sensitivity of the claim, and we periodically rerun the analysis for some of the more time-sensitive published claims and update the results. No special treatment for claims that are particularly contentious (such as whether AI writes clean code or not) -- they follow the same pipeline process. The whole concept of Lenz is to strip the emotions and biases and look only at the facts regardless of the topic.
P.S. My personal opinion on AI code quality is that it depends on who guides the AI :) It can and it does write high-quality code, and it's much easier to ensure high test coverage with the use of AI. Opus was instrumental for building Lenz.