
NeuroBlock
No-code AI Lab: Train models, access datasets, run inference
138 followers
No-code AI Lab: Train models, access datasets, run inference
138 followers
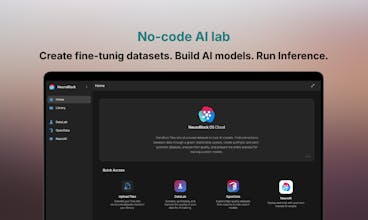
We built a no-code AI lab where you can train your own AI models with your own data. NeuroBlock OS offers an integrated ecosystem: generate and access datasets, train and deploy models, and download them to run anywhere, on your computer, server, smartphone, or through our NeuroAI cloud inference framework, ready to integrate into workflows. AI you own, cheap to run, and built to perform exactly the way you want.







NeuroBlock
Hi everyone, today we want to present what we believe should be the future of how AI is developed and integrated into businesses of all kinds.
AI is a powerful tool, but today most companies and startups are still just consuming it: large, generic models that are expensive to run and poorly adapted to real business needs.
We believe AI should be a commodity for everyone, something you can create, own, and deploy for your specific use case. AI that’s trained on your own data, fits your business, and works the way you need it to.
That’s what NeuroBlock enables.
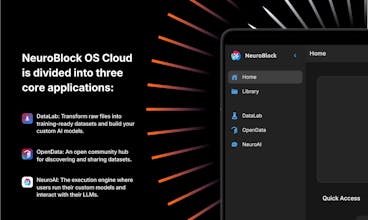
NeuroBlock is a no-code AI Lab that allows you to train custom lightweight AI models with your own data, faster and at a fraction of the cost, without relying on third-party APIs. You can create, download, and deploy your models locally, in your own cloud, or access them through a secure private API in our NeuroBlock Cloud OS platform.
Build your business on top of AI that you own, is cheap to run, and performs exactly the way you want.
Get a 7-day free trial during our Product Hunt launch: https://neuro-block.com
I’d love to hear your feedback and answer any questions! 👇
@dario_sansano Congrats to all the team! Awesome product, I love your vision and your work. Keep it up! :)
NeuroBlock
@eduardo_paya Thanks!
@dario_sansano I used NeuroBlock to train my custom AI for my startups, which finds you the best leads based on a prompt. Very happy to have been an early adopter and very proud to see this launch. Keep it up guys!
NeuroBlock
Impressive no-code approach to custom AI training. The "AI you own" positioning hits a critical pain point in today's ecosystem — especially in regulated industries where data sovereignty and model control aren't optional.
As someone building in the compliance automation space, I'm curious how you see platforms like yours adapting to domains with strict audit requirements (like finance, healthcare, or legal). Specifically:
1. Traceability & Compliance: How do you handle model lineage tracking — documenting exactly which data was used to train which version of a model?
2. Regulatory Alignment: For users in regulated sectors, does NeuroBlock support generating the documentation needed for compliance reviews (e.g., model cards, bias audits, training data provenance)?
3. Edge Deployment: Your "run anywhere" claim is powerful. How does that work in air-gapped or highly restricted enterprise environments?
Great launch — owning the full AI stack is increasingly becoming a business imperative, not just a technical choice.
NeuroBlock
@noha_elmeselhy Hi! Very interesting questions there. Right now we are focusing on the ease of use and the actual hability for anyone to train, own and deploy their own AI models with their own data.
We are exploring an Enterprise module for regulated sectors that require traceability and legal controls.
Those you mentioned would be part of that module, but as of now, that work of control, data traceability and legal compliance should be made by the said regulated company.
Something that we are going to add in the current platform however, is the hability to chose the geographic region of the inference and training cloud infrastructure as well as data storage.
Regarding the last point, if they download the models, they are the owners and they are responsible for it’s deployment and use.
Thank you for this questions, very interesting subject!
@dario_sansano Thanks The geographic infrastructure control is a smart move — solves a lot of compliance headaches before they even start.
Enterprise module sounds like the right next step for regulated sectors. That shift of responsibility upon download is exactly where most compliance frameworks start applying.
Solid approach — good luck with both tracks!
NeuroBlock
@victor_hz Thank you so much Victor, so happy to see you here. We are glad to have you among our early users!
This looks awesome, congrats on the launch! 🚀
Love the idea of having datasets, training, and inference all in one place instead of stitching tools together.
Quick question: how easy is it to bring your own data and pipelines? Definitely giving it a try.
NeuroBlock
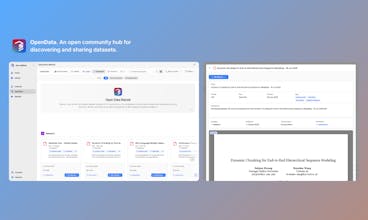
@trader_juan It’s really simple: you upload all the files you want to use to the library, select the ones for your specific model, and optionally search for related datasets to enrich your original data. Then, you create the final dataset and train your AI model.
Once it’s ready, you can use it directly on the platform, via API, or on your own device or infrastructure.
Nice profile picture by the way haha.
@carlos_mico Thanks!
NeuroBlock
Neuroblock is tackling an important problem in a smart way. I really like the focus on privacy and how they’re applying it to real use cases, not just theory. The product already feels well thought out, and with a bit more polish around UX and onboarding, it could become a very compelling solution.
NeuroBlock
@manuel97 Thank you, your feedback means alot to us!
I just came across this launch and couldn’t resist checking out the page on Product Hunt. Really interesting approach to AI, especially the ability to create your own specialized and personal models for specific subjects.
In my case, this could be extremely useful for adapting the different teaching methods I use across my learning apps for kids.
Curious to hear from the makers: how exactly do these AI models work in practice, and how do they differ from the models or APIs offered by other AI platforms?
NeuroBlock
NeuroBlock
@paula_amezquita Hi Paula, very good question! We work with lightweight 3-billion-parameter models, which means they run extremely fast and are very cheap to operate. On top of that, we use advanced training algorithms where the model’s weights (how much it actually learns from your data) adapt dynamically to the size and quality of each dataset.
As a result, you get models that outperform much larger models in the specific domain they’re trained for, while running faster and at a fraction of the cost.
For example, imagine you want to deploy an AI agent in one of your apps: a chatbot agent that teaches a specific subject to kids and interacts with them safely. Today, this usually means relying on a large third-party API, adding guardrails, building a RAG system, and managing a fairly complex data infrastructure just to make sure the model behaves the way you want, which makes your models slow and very expensive to run.
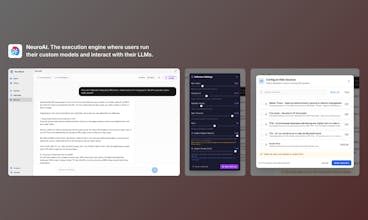
With NeuroBlock, you actually train the models yourself. That means you control how they behave "from factory", and most importantly, you can continuously retrain them with real data collected from your users. You’re fully in the driver’s seat, and unlike most other providers, the models are entirely yours.
The end result is an AI that behaves exactly the way you want, is cheaper to run, and keeps improving over time. You can integrate it very easily into your workflows: download and self-host the models and serve them via your own API, or simply use our NeuroAI inference framework API to seamlessly plug them into your apps if you dont have an AI inference server or don't wnat to mess with that.
Congrats on the launch! The project looks really interesting and it actually fits well with what I’ve been looking for, so I’m going to give it a try.
I’d love to know what you recommend for running custom models locally.
NeuroBlock
@scm24 Hi there! Awesome, we are glad you found it useful, thank you for sharing.
Until the launch of the desktop and mobile version of our NeruoAI inference framework, you can download the models and run them in frameworks like LM Studio (best option) or Ollama with some adaptations of the model file.
Thank you for your support and feedback!