
Launching today

Nirixa AI
AI observability & cost intelligence for LLM apps
25 followers
AI observability & cost intelligence for LLM apps
25 followers
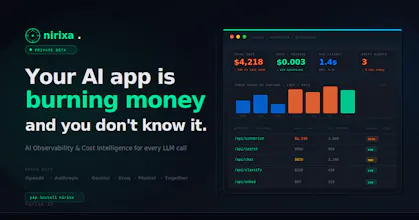
Nirixa gives AI teams full visibility into every LLM call — across OpenAI, Anthropic, Gemini, Groq, and more. Track token cost by feature, detect prompt drift, score hallucination risk, and monitor latency in real time. One SDK. One dashboard. Under 5 minutes to set up.


I run multiple LLM providers in production (Gemini Flash, GPT-4o, GPT-4o-mini) across different parts of my app and tracking cost per feature has been a nightmare. Right now I'm doing it with spreadsheets and napkin math. The token cost breakdown by feature is exactly what I need. Quick question, does it work with OpenRouter or just direct provider APIs?
@jarjarmadeit Yes! OpenRouter works out of the box. It uses the OpenAI-compatible format so Nirixa picks it up automatically, no extra config. Gemini Flash, GPT-4o, GPT-4o-mini all show up separately in one dashboard. 5 min to set up.
GitSyncPad
Hey Product Hunt! 👋
We are Aravind & Sai, builder of Nirixa (निरीक्षा — Sanskrit for
"to observe").
I built this after watching a founder friend get a
$4,200 OpenAI bill with zero idea which feature caused it.
They had no way to know. That's the problem Nirixa solves.
What we've built:
→ Token cost breakdown by feature, user & endpoint
→ Prompt drift detection (alerts when quality shifts)
→ Hallucination risk scoring per request
→ Works across OpenAI, Anthropic, Gemini, Groq & more
→ 1 SDK. Under 5 minutes to full visibility.
Launching today with a free tier (100K
tokens/month).
Two things I'd love from this community:
1. Try it → nirixa.in (free tier)
2. Tell me what you'd want to see next
Happy to answer any questions below! 🙏
Hey PH! Sai here — built Nirixa after getting burned by invisible AI costs one too many times.
The core insight: every AI observability tool today is either provider-specific (so it can't show you cross-provider comparisons) or infra-general (so it doesn't understand LLM-specific concepts like prompt drift or hallucination risk).
Nirixa fills that gap. It's a thin SDK layer that intercepts your LLM calls and tracks:
• Token cost per feature/endpoint/user
• Prompt stability over time (semantic diff engine)
• Hallucination risk score per request
• Cross-provider latency benchmarks
We're live now. Drop your questions below — especially if you're skeptical. Those are the conversations I learn the most from. 🙏