

OMNI - The Semantic Signal Engine
Reduce AI token consumption by up to 90%.
5 followers
Reduce AI token consumption by up to 90%.
5 followers
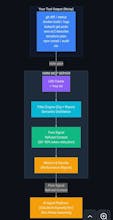
AI agents are drowning in noisy CLI output. A `git diff` can hit 10K tokens, `cargo test` 25K+ of mostly useless logs. Models read everything, but ~90% is distraction that hurts reasoning and wastes tokens. OMNI sits between your terminal and AI, filtering output in real time. It keeps what matters, understands context, and turns raw logs into high-signal input—so your agent sees the signal, not the noise.



Hi Product Hunt 👋
I’m Fajar, and I built OMNI after running into a frustrating pattern while working with AI coding agents.
They’re powerful, but they’re often overwhelmed by noisy CLI output. A `git diff` can hit 10K tokens. A `cargo test` run can dump 25K tokens of logs.
The model reads all of it, but most of it doesn’t matter.
The problem isn’t lack of context.
It’s too much noise "inside" the context.
So instead of building another “token reducer”, I wanted something that understands what actually matters.
OMNI is a Semantic Signal Engine.
It sits between your terminal and your AI, and:
- Intercepts CLI output in real-time
- Distills it into high-signal data based on context
- Preserves full raw output (no information loss)
The goal is simple:
- Give your AI less noise, without losing signal
- Improve reasoning, not just reduce tokens
Built in Rust 🦀 (moved from Zig as the system grew), MCP-compatible, and designed for real dev workflows.
Still early, but it’s already made a big difference in how I work with AI.
Would love to hear your thoughts, feedback, or edge cases where this might break 🙏