
Launched this week

Parsewise
Cursor for document work
213 followers
Cursor for document work
213 followers
Parsewise deploys AI agents that analyze entire document corpora – thousands of documents, one run. Instead of prompting single PDFs, agents extract, cross-reference, and reason across the entire batch, with every output anchored to its exact source for full traceability. No more black box reasoning. Users configure and launch agents without code, across any document type. No black boxes. No engineering. No bottlenecks.



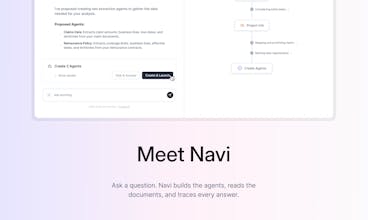






Does this handle document creation as well? Can it make a slide decks?
Parsewise
Hi Zaid (@haxybaxy ), yes! There are two ways to create documents: Via chat and via a template. The latter deterministically maps agent outputs to the template document, which makes it particularly robust. What document would you like to create?
Parsewise
Hey PH 👋 Max here, CEO & co-founder of Parsewise.
My co-founder Greg and I spent years building data infrastructure for some of the world's largest organizations. One pattern kept showing up: teams with incredibly sophisticated extraction pipelines still struggled to reason across big document corpora.
With the latest codegen tools, it only gets worse. Teams unsuccessfully finetune RAG systems and try to build custom UIs to integrate documents into chat interfaces. The results: zero business impact. Processes stay manual and error-prone while money is set on fire.
We built Parsewise to fix this. Our AI agents don't just extract data, but understand context, cross-reference across documents, and trace every answer back to the source. We call the underlying technology the Context Graph, and it's what lets Parsewise stay reliable even when documents are messy, inconsistent, or incomplete.
Today we're launching Navi, our agentic intelligence engine. Think of it as “Cursor for document work” or the analyst you always wanted: reads everything, forgets nothing, and shows its work.
Don't just take our word for it, explore the real product:
Insurance claims triage: https://demo.parsewise.ai/insurance-claims-triage
Reinsurance recoveries: https://demo.parsewise.ai/reinsurance-recovery-optimization
Investment diligence: https://demo.parsewise.ai/investment-diligence
Mortgage underwriting: https://demo.parsewise.ai/mortgage-underwriting
Sign up to try it for free at https://www.parsewise.ai/get-started
We'd love your feedback, especially if you work with complex documents. What we've built for insurance and finance applies anywhere documents drive decisions.
Follow us:
X: https://x.com/parsewise
LinkedIn: https://www.linkedin.com/company...
Parsewise
@maximilian_hofer2 excited for the launch and for bringing reliable doc based AI workflows to experts!
BlocPad - Project & Team Workspace
@maximilian_hofer2 this is really cool. The idea of having an AI agent that actually understands context across thousands of docs instead of just one at a time is a huge deal. Curious if you're seeing teams use this more for internal knowledge bases or external-facing docs?
Parsewise
Hi @mihir_kanzariya , right now, we find teams use Parsewise most for case-based documents (e.g., large insurance claim, technical due diligence, KYC case). However, we also have customers deploy our agents on internal knowledge bases to make documents in file systems usable for analytics and benchmarking.
What use case is top of mind for you? Let me know if it's helpful to dive deeper.
The idea of agents reasoning across multiple documents instead of just extracting fields sounds much closer to how real analysis works. I also like the focus on traceability back to the source. How does the Parsewise handle conflicting information between documents when generating an answer?
Parsewise
Hi @vik_sh , we exhaustively process all documents. For each match, we resolve to a single answer. During resolution, we automatically detect conflicting information and flag it to the user. Sometimes, conflicting information is solved by being more specific about what you're looking for. Sometimes, it's an inherent inconsistency in the underlying data.
Parsewise
@vik_sh thank you and good question!
We have explicit instructions for conflict resolution and a proactive process to flag any unresolved conflicts. The reason for this is that you cannot always know ahead of time what the correct rule is (newer vs older document, different source prioritization), so we need to make it interactive and configurable by the expert.
Trufflow
This is so interesting. Especially since documents can contradict one another or become outdated. Are there ways to "monitor" a specific topic and flag whenever contradictory documentation is circulated?
Parsewise
Hi @lienchueh , monitoring "topic drift" is a key feature of our platform. Each agent re-evaluates new data against existing outputs and flags any contradictions or inconsistencies. Users can provide guidance as to what makes for an inconsistency, which is particularly useful for qualitative topics. What topic are you interested in monitoring? Let me know if it's helpful to dive deeper.
Curious how Parsewise handles document storage on the backend — are you keeping files in your own infra or delegating fully to object storage like S3 with client-side encryption? Asking because document tools that start shared tend to hit access-control edge cases fast once teams get bigger. Super clean concept either way.
Parsewise
@avinash_matrixgard thank you!
By default it is S3 and definitely know what you mean, in Palantir we had to deal with a lot of that complexity.
For us it's somewhat simpler because enterprise clients require being on their infra anyway.
Congrats on the launch! This is something I've been looking for! Does it also work on the browser?
Parsewise
@abhinavramesh Hi Abhinav, you can sign-up and use on your browser here: https://www.parsewise.ai/get-started
Parsewise
@abhinavramesh yes the platform works in the browser. You can either upload documents directly or you can also enable web search within Navi
This is interesting! How does Parsewise handle conflicting information across documents in a corpus?
Parsewise
Thanks @athanzhang !
Regarding your question on conflicts, it's a good one because we see it happening quite a bit.
We have explicit instructions for conflict resolution and a proactive process to flag any unresolved conflicts. The reason for this is that you cannot always know ahead of time what the correct rule is (newer vs older document, different source prioritization), so we need to make it interactive and configurable by the expert.