
Launching today

Flux
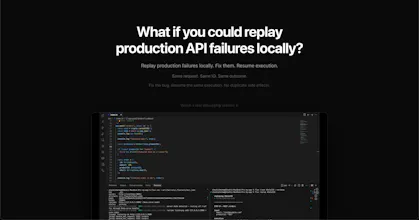
Fix production bugs by replaying them locally
77 followers
Fix production bugs by replaying them locally
77 followers
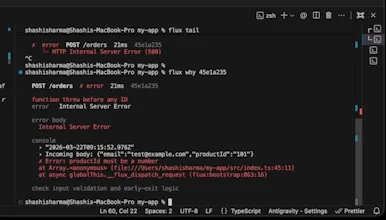
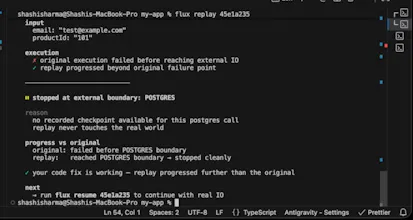
Flux records API executions so you can replay failures locally, fix them, and resume execution safely. Instead of guessing from logs, you get the exact request, inputs, and behavior. Same request. Same IO. Same outcome.
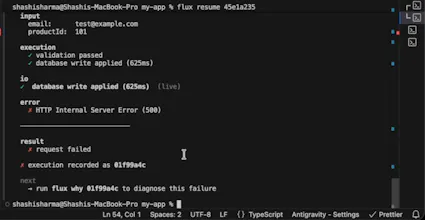

Flux
Flux
One thing that surprised me while building this:
The hardest part wasn’t capturing requests — it was making them replayable deterministically.
Especially when:
- external APIs change
- async workflows are involved
- retries behave differently
That’s where most debugging tools break.
Curious — for people working with APIs or AI pipelines:
What’s the hardest bug you’ve had to debug in production?
@shashisrun Had a webhook that started sending different payload shapes on weekends. The third party's A/B testing was hitting a different serializer, but only on Saturdays. Took two days of adding logs and waiting for the next Saturday to reproduce it. Staging never saw it because their test environment didn't have the same A/B config.
Being able to just replay the actual request would've cut that from days to minutes.
Flux
@alan_silverstreams that’s such a perfect example — the “only on Saturdays” bugs are the worst 😅
A/B configs + third-party behavior is exactly where things become impossible to reproduce reliably.
And yeah — that’s the core idea. Instead of adding more logs and waiting for it to happen again, just replay the exact request with the same context.
Curious — in cases like this, do you usually end up adding more observability, or building custom replay/debug tooling internally?
@shashisrun How do you deal with non-deterministic bits like timestamps or external API flakiness during replay?
Flux
@swati_paliwal great question — this is actually the hardest part.
What I’ve been doing is separating deterministic vs non-deterministic parts of execution.
– For things like timestamps/randomness → they get recorded and replayed as-is
– For external APIs → responses are captured and stubbed during replay
– For retries/async flows → the sequence + timing is preserved from the original execution
So instead of trying to simulate behavior, you’re effectively “re-running” the same execution with controlled inputs.
Still evolving this, but that’s the general approach so far.
The resume-after-fix part is the piece I haven't seen before. Most replay tools let you reproduce the bug, but you still have to re-trigger the whole flow manually. How does the resumption work in practice - does Flux hold state between the failure and the fix, or is it more like re-running from a checkpoint?