

SCRAPR
The data layer for the agentic web
367 followers
The data layer for the agentic web
367 followers
SCRAPR is a new approach to web data extraction. Instead of relying on fragile DOM selectors or heavy browser automation, SCRAPR looks at how modern websites actually load their data and extracts structured responses directly from those sources. The goal is to make web data pipelines faster, more reliable, and easier to maintain. Right now SCRAPR is in early MVP and we’re looking for developers, data teams, and AI builders who need clean structured data from websites.
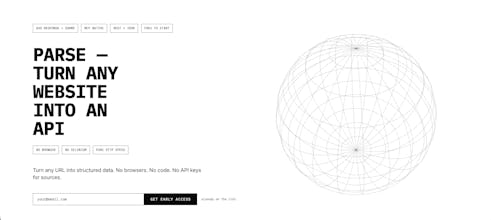
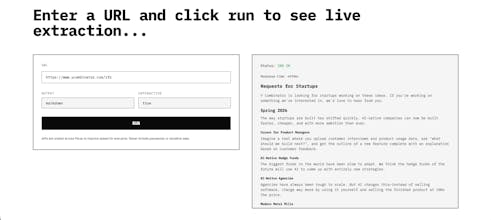

Looks cool — but how well does it actually handle hard targets like Cloudflare, JS-heavy sites, proxies, and rate limits in the real world?
SCRAPR
SCRAPR
How does this engine handle JavaScript-heavy or dynamic content without a browser, and what mechanisms ensure data accuracy when the source website changes its layout?
SCRAPR
rtrvr.ai
So what happens when the API changes?
Sites like Linkedin also use server side rendering and hydration for pages so this approach won't work on most websites?
SCRAPR
@arjun_chintapalli Good question. If an API changes, SCRAPR isn’t tied to just one extraction path. It can re-analyze how the page delivers its data and adjust instead of relying on a fixed endpoint or selector.
And you’re right that some sites use server-side rendering or hydration. In those cases the content still exists in the page response or in subsequent requests, so SCRAPR can fall back to extracting it from the page structure when needed.
AutonomyAI
This is such a clean solution to a problem that's been annoying developers forever. Rooting for you!
SCRAPR
The network-call interception approach is genius. Most scrapers fight against the rendered HTML which is a losing battle - sites redesign constantly and JS-rendered content is a nightmare.
Going upstream to the actual data source (API calls) means you're getting the same clean data the site itself uses. Much more stable.
How do you handle authentication-required data? Like scraping my own logged-in dashboards to aggregate data from various services I use?
This is such a smart pivot from the usual DOM-parsing headaches! As a dev who's spent way too many hours fixing scrapers because of a tiny CSS change, focusing on the data responses directly sounds like a lifesaver. How do you handle sites with heavy anti-bot protections or obfuscated API endpoints?