
Launching today

Struct
AI agent that root-causes engineering alerts
373 followers
AI agent that root-causes engineering alerts
373 followers
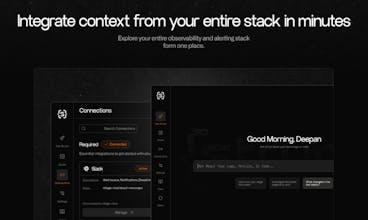
Struct is an AI agent that root-causes engineering alerts using logs, metrics, traces, and code. Resolve incidents faster with a composable, customizable system that deploys in minutes and works with your existing DevOps workflows.


Struct
Hey Hunters!
We're Deepan and Nimesh, co-founders of Struct. Today we're excited to launch the on-call agent every team deserves -- for free!
If you've been on-call, you know the drill: alert fires, you open Datadog (or Grafana, or whatever), hunt for spikes, grep through logs and code, loop in a senior engineer...rinse & repeat. Meanwhile, noisy alerts never get tuned and customer issues slip through.
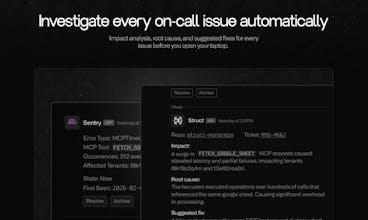
Struct gets you from alert → root cause before you even open your laptop.
Within minutes of an alert firing, Struct:
✅ Pulls relevant metrics, logs, traces, monitors, and code
✅ Does a regression analysis and correlates anomalies and spikes
✅ Replies with with a root cause, impact summary, and pattern analysis
✅ Drafts a full incident report with dynamically generated charts, timelines, and commit histories
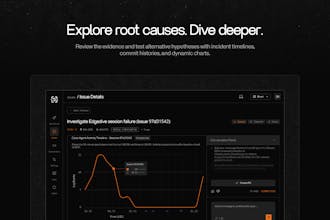
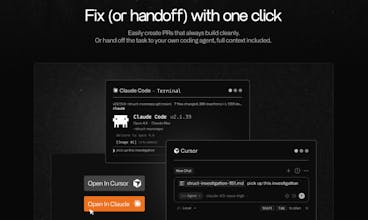
Dive deeper in Slack or our app. Or handoff the full context to your favorite coding agent to ship a fix in one-click.
We built Struct for lean teams without an SRE, and orgs going all-in on AI dev workflows — companies like FERMAT and Arcana already use Struct to auto-investigate thousands of alerts monthly and give every engineer the context to handle incidents on their own.
Five minute set up, integrates with every leading observability platform plus Slack, GitHub, Linear, Claude Code, and fully SOC 2 Type II and HIPAA compliant.
Get started free at struct.ai — no credit card required.
Questions? Hit us in the comments - we'll be around all day. Or shoot us an email at founders@struct.ai.
And as a special thanks to the Product Hunt community, if you upgrade to a paid plan, use promo code HUNTSTRUCT for 20% off for the next 3 months! 🔥
Alert fatigue is the thing nobody warns you about until you're waking up at 4 am to a page that turns out to be nothing. If this can automatically trace an alert back to its root cause, that saves hours of digging through logs and dashboards. I've had incidents where the alert fired on a symptom three layers removed from the actual problem. How does it handle cases where the root cause is outside your codebase, like a third-party API degradation or a DNS issue?
Struct
@aitubespark thanks for the question. the short answer is that it works surprisingly well!
because it's able to autonomously do web research, it can actually, for example, pull up status pages for third party services. it can often also identify flakiness vs. more serious regressions in third party APIs by examining patterns of failed and successful calls. last week, it actually identified a serious degradation in slack's web_mention webhook hours before they updated their status page.
the caveat is that it's limited by the context that it has access to.
Struct
@aitubespark Could not agree more. Our agent operates iteratively, coming up with hypotheses, challenging them, and looking for evidence to validate or invalidate them at every layer. When it identifies degradation of third party services, it validates against authoritative sources, like status pages, to confirm outages.
Snippets AI
The gap between "alert fires" and "engineer understands what actually broke" is where most incident response time gets wasted — correlating metrics, logs, and traces across services is exactly the kind of tedious cross-referencing that AI should handle. The one-click handoff to a coding agent to ship the fix is a compelling end-to-end vision — how well does that work today for non-trivial root causes that span multiple services?
Struct
@svyat_dvoretski Great question! Multiple services is exactly where this becomes so powerful. Struct is able to string together logs across different services from different observability providers using encoded correlation techniques (e.g. querying by correlation ids, querying for known logs, sifting through a time range, etc.) which is ordinarily a tedious process. It constructs a timeline of the issue and iteratively goes deeper to establish a definitive root cause. It memorizes successful debugging techniques for each customer's unique architecture, which makes it get even better over time. Our customers working at a large scale with many services are already reporting an 80% reduction in triage time.
@svyat_dvoretski @nimeshmc Struct pulling logs, metrics, traces, and code into a single root cause analysis is the hard part. Most teams settle for manual grep workflows and siloed dashboards. The regression analysis plus correlation across telemetry sources is where on-call time gets reclaimed. The pattern memory angle, learning from past incidents to improve future investigations, compounds value as your architecture gets messier. The edge case to watch: root causes spanning uninstrumented service boundaries where Struct can't pull telemetry.
Struct
@svyat_dvoretski @piroune_balachandran Absolutely. Struct can provide a hypothesis with next steps to confirm evidence from sources it doesn't have access to, which is useful in itself to provide engineers guidance for where to look. That is often the hard part for really messy issues; the fix itself is usually simple.
I'm a software developer who works with AI. Could you give me a specific example of how your software could help me? I've read through your site, but I don't quite understand what exactly you do.
Struct
@daniyar_abdukarimov Hi Daniyar! Of course. Many customers have a slack channel that they have alerts posted to when their monitoring tells them something might be wrong. We monitor that, investigating each one based on your code and the logs + metrics outputted in production and deliver an understanding of how it is impacting your customers and what specifically caused the issue. One example:
Alert comes in: out of memory crash occurred
Struct pulls the logs + metrics relevant to this alert and correlates it with what your code does
In 5 minutes, it posts a message back to the Slack thread with "Commit abcd1234 introduced a memory leak in the caching layer that increased memory usage over 30 minutes, eventually causing container restarts. 214 users received 5xx errors during container restarts."
Riveter (YC F24)
This is awesome! It would be great to manage my Sentry anxiety and take work off my plate. Are you all mostly for enterprise or does it work for small teams, too?
Struct
@abbygrills absolutely! we built our self-service tier so small teams can get set up and running in <10 minutes for free. if you have any issues getting set up, just reach out.
Does Struct actually build a dependency graph across your infra or just pattern-match on the alert text? I've got microservices that can fail in three different systems depending on the blast radius, and I'm curious if it traces downstream impacts or just points to the loudest screaming dashboard.
Struct
@lliora Yes! It builds an internal understanding of how your services work together by utilizing your code and observability data. This isn't a simple surface level attempt at pattern matching known exceptions and alerted symptoms. Our agents trace through what actually happened in production, going iteratively through layers of services until they find definitive evidence of the root cause. Most of our customers have several services deployed in production with observability data in different places. We tie them all together.
Cekura
Amazing team!
We signed up with them early on and have been a fan since. It's a game changer in terms, helps team ship fixes instantly and reduces the nightmare that on-call is