

Cekura
Automated QA for Voice AI and Chat AI agents
1.8K followers
Automated QA for Voice AI and Chat AI agents
1.8K followers
Cekura enables Conversational AI teams to automate QA across the entire agent lifecycle—from pre-production simulation and evaluation to monitoring of production calls. We also support seamless integration into CI/CD pipelines, ensuring consistent quality and reliability at every stage of development and deployment.
This is the 3rd launch from Cekura. View more
Cekura
Launched this week
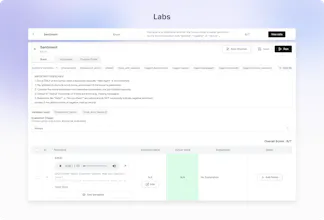
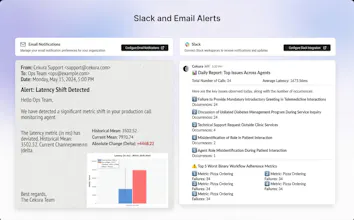
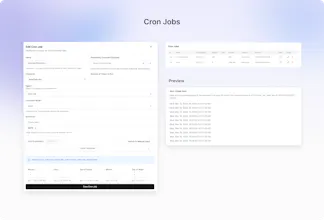
Out-of-the-box 30+ predefined metrics for analysis on CX, accuracy, conversation and voice quality. Compile perfect LLM judges by annotating just ~20 conversations and auto-improve in Cekura labs. Real-time, segmented dashboards to identify trends in Conversational AI. Smart statistical alerts so that you get notified only when metrics shift from historical baselines. Automated system pings to catch silent production failures.

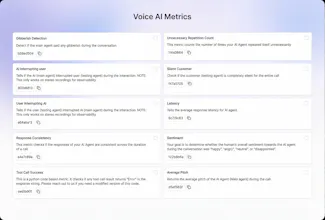


Free Options
Launch Team / Built With







ConnectMachine
Would love an API-first version of this for deeper integration into internal tooling.
Cekura
@syed_shayanur_rahman We already have APIs available for integration - can refer here: https://docs.cekura.ai/api-reference/observability/send-calls
Are these prefedined metrics all on Audio or text based ?
Cekura
@dhruvjaglan Its a mix. All the voice specific metrics (Silence, latency, interruptions, pronunciation issues etc) need audio. Accuracy metrics (relevancy, hallucination, reponse consistency etc) is text based
Cekura
@dhruvjaglan Some are on text and some are on voice
Congrats on the launch, team!
What are the challenges come when teams tries to build this internally?
Cekura
@himank_jain1 Building and optimizing each metric over a dataset takes months of engineering left and fine-tuning. Lot of these metrics are not even LLM based but uses huerestics and statistical models. Having said that, team can build a basic analytics dashboard if voice metrics or smart alerts is not that important and they only need to analyze few specific workflow metric only
Cekura
@himank_jain1 Another challenge arises when a new LLM enters the market. If we want to switch because the new model is better or because the old one is being deprecated—we have to re-optimize all our prompt metrics against the eval set, which is a huge undertaking. This makes the eval set the most important factor; it stays constant, while the prompts change regularly to adapt to new LLMs.
Spill
Love the sped at which this team ships! I was curious do you also have plans to roll out observability for images/video agents?
Cekura
@vishruth_n Currently we are focussed only on voice and chat modality. We have it our vision to support simulations and observability across modalities
Congrats team!!! Do you support real-time streaming analysis or is it batch processed right now?
Cekura
@himani_sah1 Currently we support post call - we can fetch the call via webhook as soon as it over. You can also send it in batches if preferred.
Super excited for this !!
How many predefined metrics are relevant for chat as well ?
Cekura
@nabonita_dash All customer experience and accuracy metrics are applicable on chat (Response Consistency, Relevancy, Hallucination , Tool Call Success, Sentiment etc)
Is the metrics customizable @kabra_sidhant
Cekura
@humza_sheikh1 You can define Python-based custom metrics in Cekura with direct access to all processed call data, so you measure exactly what matters to you. You can also define your own success criteria using a rubric-style setup tailored to your use case. The platform is fully modular, so you can go from full automation to fine-grained control depending on what you need.
Cekura
@humza_sheikh1 @janhvi_nandwani1 Just to add to it - you can even use our pred-defined metrics for eg: interruptions to define your success criteria. eg: if agent interrupts customer more than n times in the call, you can define an interruption metric failure