
Launched this week

ContextPool
Persistent memory for AI coding agents
290 followers
Persistent memory for AI coding agents
290 followers
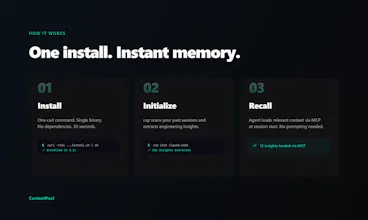
Every AI coding session starts from scratch. You re-debug the same bugs, re-explain decisions you already made. Your agent forgets everything. ContextPool gives your agent persistent memory. It scans your past Cursor and Claude Code sessions, extracts engineering insights (bugs, fixes, design decisions, gotchas), and loads relevant context via MCP at session start. No prompting needed. Works with Claude code, Cursor, Windsurf, and Kiro. Free and open source - team sync available for $7.99/mo.






Vibe-coder here. I maintain a claude.md file and update it manually at the end of every session. It's manual, but it works. For a solo builder (no team) what does ContextPool give me that a well-maintained claude.md doesn't?
probably the extraction part — you document what you think matters,
but i'd guess it catches stuff you'd never think to write down (that
random 2am gotcha that took 3 hours). @majidyusufi curious — what
happens with low-signal sessions, does it still store something or is
there a quality threshold?
ContextPool
@majidyusufi @webappski That 2am gotcha is exactly the sweet spot, the stuff that never makes it into docs because by the time you fix it, you just want to sleep.
On low-signal sessions: there is a quality threshold. Not every session produces a summary worth storing. If a session is just routine edits with no meaningful decisions, patterns, or debugging, it doesn't add noise to the pool.
@majidyusufi @webappski thanks, that makes sense I don't always know what's worth documenting until it breaks again.
This solves a genuine pain point. I run a small agency and every time I spin up a Claude Code session on a client project, I spend the first 10 minutes re-explaining the stack, the deployment quirks, and why we made certain architectural choices. The idea of capturing that as structured, searchable memory rather than just dumping everything into CLAUDE.md is a much cleaner approach. Curious about one thing: for the team sync at $7.99/mo, is there a way to scope shared memory per project or repo? In an agency setting, you definitely don't want client A's context leaking into client B's sessions.
What I've used so far that works very well for me is the compound part of Compound Engineering. The problem I see to CE is that it's per repo, ContextPool looks amazing since all my repos can share these eng learnings!
Great work!
And what if I had multiple projects in Claude Code? How do you handle that?
UXPin Merge
Interesting concept, but “exhaustive scanning” sounds expensive at scale. Curious how it performs with large document sets in real production use.