
Launched this week

QuickCompare by Trismik
Compare LLMs on your data, measure, and pick the best.
268 followers
Compare LLMs on your data, measure, and pick the best.
268 followers
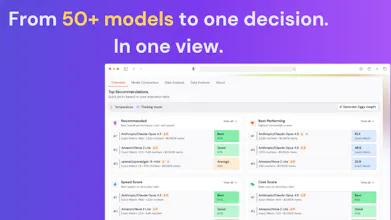
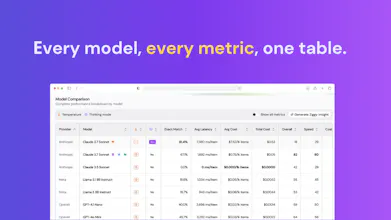
Stop guessing which LLM to use. Upload your data, compare 50+ models, and see quality, cost, and speed side by side. Pick the best model for your use case without manual testing or generic benchmarks.



ZeroHuman.
Excited to hunt QuickCompare today.
QuickCompare helps teams choose the right LLM based on how models actually perform on their own data. Not generic benchmarks.
You upload your dataset, select the models, and get a side-by-side view of performance, cost, and speed.
What stands out here:
• Real evaluations on your own prompts and use case
• 50+ models compared in a single workflow
• Clear trade-offs between quality, cost, and speed.
• No manual scripts or ad-hoc testing
If you’re building with LLMs and tired of guessing which model to use, this is definitely worth checking out.
QuickCompare by Trismik
Hey Product Hunt, Rebekka here, co-founder at Trismik 👋
We built QuickCompare because we kept seeing the same pattern: teams shipping LLM features were making model decisions with surprisingly little evidence.
Often, they were defaulting to the biggest or most familiar models, relying on public benchmarks, or testing a couple manually and calling it a day. But in practice, that can mean spending far more than necessary on inference without actually getting the best result for your use case.
The reality is that model choice is rarely one-dimensional. It is not just about which model performs best. It is also:
• Which model performs best on your prompts and tasks?
• Where can you cut inference cost without sacrificing output quality?
• When do cheaper models actually match or outperform the expensive default?
• How do cost, speed, and task performance trade off side by side?
For many teams, especially those building AI products at scale, this has real business impact. Huge monthly inference bills, slow experimentation, and too much guesswork in a decision that directly affects margins, product experience, and speed to market.
That is why we built QuickCompare.
QuickCompare helps teams compare models on their own data, side by side, across quality, cost, and speed, so they can make a confident decision based on their actual use case, not generic benchmarks.
And we also built Ziggy, our AI Scientist assistant, to make this much easier. You don't need deep evals expertise to get started. Ziggy helps you set up and run comparisons in a much more intuitive, no-code way.
The goal is simple: help teams find the right model for the job, often cutting cost dramatically while maintaining or even improving performance and speed.
If you're building with LLMs, we'd really love your feedback. In particular, I would love to hear:
• how you are choosing models today
• whether inference cost is a major pain point for you
• what makes model evaluation feel slow, difficult, or inaccessible in practice
🔗 Try QuickCompare free: We’d love to hear what you think 🙏
🎁 Product Hunt bonus: Get an extra $10 in free QuickCompare credits
Thanks so much for checking us out and supporting the launch!
QQ: who's the buyer?
As a solo founder I picked one model and stuck with it because the switching cost (prompt re-tuning, eval
rewriting) usually outweighs the marginal gain.
Comparing 50 LLMs feels like enterprise eval-engineer kit.
What's the indie use case I'm missing?
I have only today adopted Codex, partially into my stack, just because Claude is too slow for some things.
QuickCompare by Trismik
@naumaan_zahid Yeah, I think that’s right for most solo builders - picking one model and sticking with it is usually the right default.
Where we’re seeing people use this isn’t “compare 50 models”, it’s more:
– “This got slower/worse recently - is there a better option?”
– “Is there a cheaper model that’s good enough for this specific task?”
Sometimes the improvement is marginal as you said, but we’ve also seen AI teams save a lot of money by switching models where the cheaper option performs just as well for their use case. And with inference now becoming one of the biggest cost drivers for many AI products, those checks can really add up.
With QuickCompare you can just throw 2–3 models into a quick check, get a signal, and avoid rebuilding your eval setup every time.
We happen to support a lot of models, but that’s more so you’re not blocked when you do want to check something.
Curious btw, what felt slow with Claude for you?
ive been running gpt-4o-mini in production for sentiment scoring on my crypto site, and the question i actually care about is "would switching to claude haiku save me money without tanking quality on MY prompts". Does quickcompare measure cost per call and tail latency alongside output quality, or just output quality ?
QuickCompare by Trismik
@vincentf Great question! Yes in addition to output quality which you could measure with LLM-as-a-Judge it measures cost per call and tail latency so hopefully you're covered on this. We're no longer running gpt-4o-mini but we have a wide range of other GPT models you could try in addition to Haiku 4.5 such as 4.1 Nano, 4.1 Mini or OSS 20B if you prefer open source - all these would offer savings on Haiku if they match up on your criteria.
Having actual metrics on your own data instead of generic benchmarks changes the conversation completely. Quick question: can you test with complex prompts that include system instructions and multi-turn context, or is it more suited for single-turn comparisons? A lot of our use cases involve long system prompts with specific persona instructions, and that's usually where models diverge the most.
QuickCompare by Trismik
@ben_gend That's great feedback thanks Ben - yes we're hearing a lot that it's real user data that's driving decisions.
On your question: today QuickCompare's strongest for single-turn evaluations, and we don’t yet have first-class support for structured prompts or true multi-turn flows. You're pointing to a really important need.
For multi-turn contexts like agent flows or customer interactions, you can approximate some of this in the current version by comparing different prompt setups. For example, you could test Turn 2 on its own versus Turn 1 plus Turn 2 etc, and compare how models behave as more conversation state is introduced.
That’s not the same as native support for system instructions, persona layers, and multi-turn context - and we think those are exactly the kinds of scenarios that matter most in practice.
If you'd be open to it we'd love to hear more about your use case: https://calendly.com/d/ct5c-zdm-ny2/quickcompare-support-session
QuickCompare by Trismik
Hi Product Hunt! I'm Alice, on the Science team at Trismik. Big day for us today, and I've been looking forward to sharing what the whole team has built.
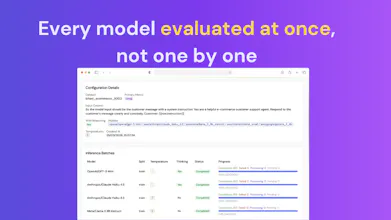
The shape of QuickCompare is a four-step flow: bring a dataset, configure how you want to evaluate (which metrics, which columns, optionally an LLM-as-Judge), pick the models you want to compare, then run them all in parallel against your data. What you get back is a side-by-side view of accuracy, inference cost, and average latency for each model, plus a breakdown of how each one performs on the easier vs harder slices of your dataset rather than just the headline average. The "your dataset" bit is the point: it's an LLM evaluation tool that scores models against your actual task, which we think is what makes it a more useful LLM Arena alternative for teams who have their own data and need a real answer rather than a popularity vote.
Ziggy is the AI assistant inside QuickCompare, and the part I've spent most of my time on. It exists because most LLM evaluation tooling assumes you already know your way around prompt templates, judge prompts, and which metric makes sense for which task. That's a pretty steep tax for someone who just wants to know which model is cheapest at acceptable quality on their data.
So Ziggy looks at your dataset, suggests sensible columns and metrics, writes the Jinja2 input template, and if you need an LLM-as-Judge setup it drafts the judge prompt with a scale that fits the task (binary for classification, 1 to 5 for open-ended generation). You can chat with it the whole way through and it knows where you are in QuickCompare, what you've already filled in, and what's still missing. Once the run finishes, it switches into analysis mode and helps you interpret the cost, latency, and accuracy numbers across the models you ran.
Has anyone had a model you assumed was the right call turn out not to be once you actually tested it? That gap is the bit I find most interesting and would love to hear stories.
Thanks so much for supporting us today, and do give QuickCompare (and Ziggy!) a try 🙂
Klariqo AI Voice Assistants
Great launch! Btw, can I compare models for specific tasks like marketing, coding, or support?
QuickCompare by Trismik
@ansh_deb Hi! Absolutely. You bring a dataset that represents the task you care about (or select one from Hugging Face), Ziggy helps you pick a sensible metric or set up an LLM-as-Judge, and QuickCompare runs the models you've picked against your data and reports back the performance. LLM-as-Judge in particular makes this easy for the more open-ended tasks like marketing or support, where there isn't always a clean right answer to compare against.