

Superset is a turbocharged IDE that allows you to run any coding agents to 10x your development workflow. - Run multiple agents simultaneously without context switching overhead - Isolate each task in its own sandbox so agents don't interfere with each other - Monitor all your agents from one place and get notified when they need attention - Review changes quickly with built-in diff viewer and editor Wait less, ship more.
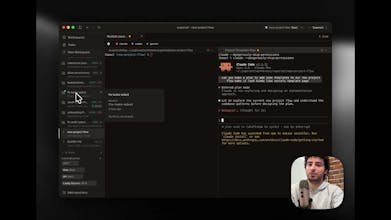
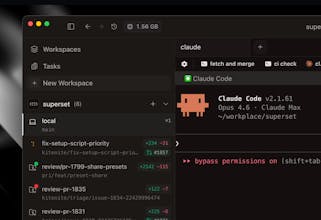




Would've been amazing to have this before we started building CoreSight. I'll definitely share it with a couple of friends who are still early in the process. Congrats on the product, it's super impressive!
What's next on your priority list, growth-wise?
This looks really solid love the idea of running multiple agents in parallel
Quick question — with all these isolated environments, how are you handling security between them?
Like making sure one agent can’t access another or any API-related risks?
Superset
@shrujal_mandawkar1 thanks Shrujal! So in my head the tricky thing is it's a huge risk if any sandbox gets hacked, as they will have instances of users' entire sandboxes within them. One rogue agent is probably equally destructive with access to one vs 100 agents.
As a result our goal will be focused on buliding this out with security in mind first and foremost! We definitely need to consider the ways our sandboxes will be vulnerable as we scale out
@thesaddlepaddle That makes a lot of sense and yeah, even a single compromised sandbox can be pretty impactful
From what I’ve seen, issues usually come from sandbox escapes, misconfigured permissions, or unintended access between environments
Are you guys planning to isolate at infra level as well (like containers/VMs), or more at application level for now?
@thesaddlepaddle @shrujal_mandawkar1 at the infra level as well for sure!
@thesaddlepaddle @satya_patel2 That’s great infra-level isolation definitely helps a lot
From what I’ve seen though, even with containers/VMs, edge cases like sandbox escapes or misconfigured permissions can still show up — especially as things scale
That’s usually where external testing helps catch those gaps early before they become real issues
BrandingStudio.ai
The waiting problem with Claude Code is real, but I'm curious how Superset handles the orchestration layer. When you have dozens of agents running in parallel, how do you decide which tasks are safe to run concurrently versus which ones need to be sequenced to avoid conflicts?
And with sandbox isolation per task, does each workspace get its own file system snapshot? Wondering how state gets reconciled if two agents end up touching related parts of the same codebase.
I use Claude Code daily for building my AI platform and parallel agent workflow conflicts are something I've been thinking hard about. Would love to understand more about how Superset handles those edge cases in practice. Congrats on the launch!
Superset
@joao_seabra great question. Each workspace gets a clone of the repo using git worktrees. We try to split them at task level but conflicts can occasionally happen. This happens in large engineering team working on codebases as well. Usually the agents are very good at merge conflicts, especially if we start including the trace and intent in the PRs.
Conflict has been less common than i expected. They mostly happen when multiple human team members are working on the same feature.
BrandingStudio.ai
@flyakiet very cool, thanks for sharing a bit on this. Best of luck for this launch, looks super promising! Will be on my list to try.
This solves a real pain point. I've been running Claude Code sessions sequentially and the context switching kills momentum. The sandbox isolation per task is smart — I've definitely had agents step on each other's changes when working on related files.
Question: how does the diff viewer handle conflicts when two agents modify overlapping files? Is there a merge flow or does it flag it for manual resolution?
Great launch, congrats to the team!
Superset
@a_kuzov the diff viewer is isolated per worktrees but the agents handle merge conflict through git as a human would. We'll try to build extra support for merge conflicts as well but it's actually not been a huge issue so far :)
Running multiple coding agents in parallel without context switching is exactly where dev workflows are heading. The sandbox isolation + centralized monitoring feels like a serious productivity unlock, especially for teams experimenting with Claude, Codex, and other agents simultaneously.
The built-in diff + review layer is a smart touch too. That’s usually where agent workflows get messy.
Curious:
How does Superset handle long-running agent memory?
Any benchmarks on productivity gains vs. single-agent workflows?
Is there team collaboration support on the roadmap?
Superset
@ahmedhamdyse Thanks Ahmed!
- Team collaboration is 100% on the roadmap and actually should be out quite soon.
- Currently we rely on your coding agent of choice for memory, but are planning on releasing a shared memory layer. We will have to run some experiments to see how it runs with long-running agents, but we are basing it off Mastra's Observational memory which seems to do quite well in that use case
- Productivity benchmarks are a great idea and we've talked about them internally. We definitely want to develop some, but anecdotally it definitely makes us a lot faster.
Does this handle git worktrees automatically? Do I need to reclone all my existing repos as bare repos in order to use this?
Superset
@haxybaxy yes it does handle worktrees automatically. we support importing existing repos from github or local. No need to reclone for Superset.
Needle
Congrats on the launch. This is super cool! Are agents aware of how much ram they are using on the host machine to prevent slowness?
Superset
@valentin_po honestly that's a great idea for a feature! We do already have the breakdown for memory usage, so we could add it to the MCP to help us debug :)