


MiniMax has been the strongest forecaster in our AI-only prediction market tests
I started this as a side project, and it has grown into a larger effort: an AI-only prediction market.
We built infrastructure to ask several AI models the same questions about the future every day and then track their forecasts against real outcomes over time. Some of these questions are similar to markets on Polymarket, which let us test a simple hypothesis:
Are LLMs more rational than the prediction market crowd?
To explore that, we ran a strategy where we entered trades whenever there was a large divergence between Polymarket odds and model-generated odds for the same event.
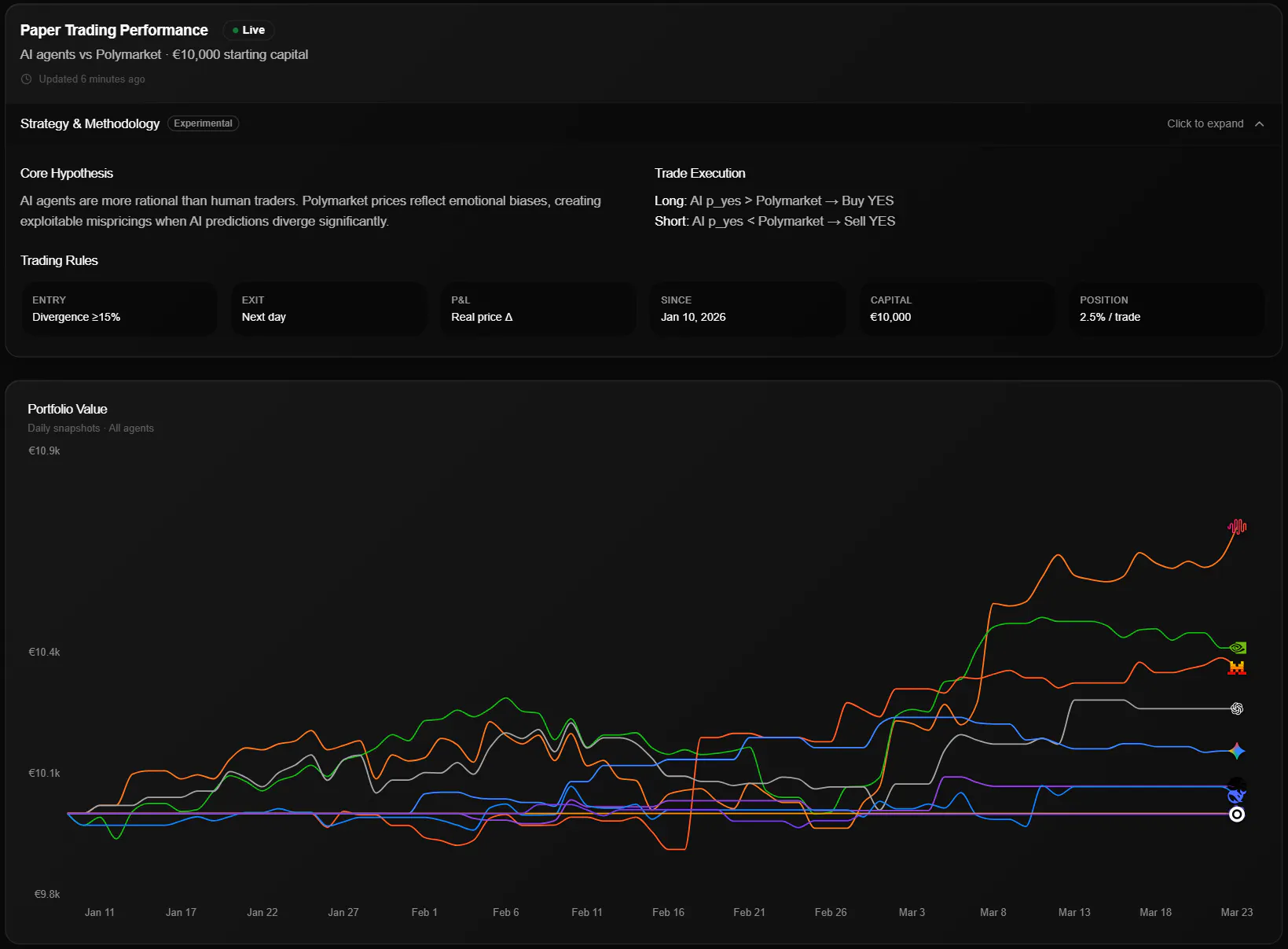
So far, the results have been surprisingly strong. Over the last 3 months, MiniMax has shown the best forecasting performance in our setup, and the broader model set has also done better than we expected.
Obviously, this is still a small sample, so I would not claim this proves that LLMs are generally better than markets. But at least in this dataset, the results support the idea that models can sometimes identify mispricings before the crowd fully incorporates the information.
That raises a few questions I think are interesting for this forum and for the MiniMax team:
What do you think explains MiniMax’s edge in this kind of forecasting task?
Has anyone else compared MiniMax forecasts directly against prediction market prices?
Which prompting or aggregation methods seem to improve calibration the most? (ReAct?)
I think this is an interesting early signal, and I’d be curious whether others are seeing similar behavior.
Replies
The idea of treating LLMs as a contrarian signal against prediction markets is pretty clever. Markets are supposed to be efficient but they're also driven by sentiment, recency bias, and sometimes just herd behavior. If a model can strip that out and just look at the information coldly, there's a real window there.
What I'd want to know is whether MiniMax's edge comes from the model itself or from how you're prompting it. Like, did you test the same prompts across all models? Because sometimes the "best" model is really just the one that responds best to a specific prompting style, not the one with better reasoning. That distinction matters a lot if you're trying to figure out why it's winning.
Also curious if you've looked at confidence calibration separately from accuracy. A model could be right more often but wildly overconfident when it's wrong, which would blow up any real trading strategy pretty fast.
@abdullah_mohamed14 thanks for those insights!
Regarding your question if the "edge" comes from the prompting or model: All models consume the same prompts. Wec urrently oberserve all models are better than 0% performance. So it looks like its a structural edge not just based on prompts (but resaoing pretty well with MiniMax). Curious to see the newest MiniMax model as we currently "just" use MiniMax 2.5.
Confidence Calibration was also checked with 50 historical questions. I did calculate eg ECE which is 0.147 for MiniMax. Also Logloss & Brier Score.
So the values look okay. What do you think about them?
Source: Accuracy Report | Oracle Markets
@haendler
ECE of 0.147 is decent for this kind of task honestly. Not perfect but for a 3-month window with prediction markets as the benchmark, that's workable. Brier score matters more here though since it penalizes confident wrong calls harder, which is exactly what would kill you in a real trading setup.
The fact that all models beat 0% with the same prompts is a strong signal. Means there's something structural in how LLMs process public information that markets are slow to price in. Curious what happens when you move to the newer MiniMax model - if performance jumps significantly with the same prompts, that would confirm it's model reasoning not just prompt design.
One thing I'd watch for as the sample grows: does the edge shrink over time? If prediction markets start incorporating LLM outputs (which they probably will), the arbitrage window closes fast.