


MiniMax M2.7 vs. Claude Opus 4.6
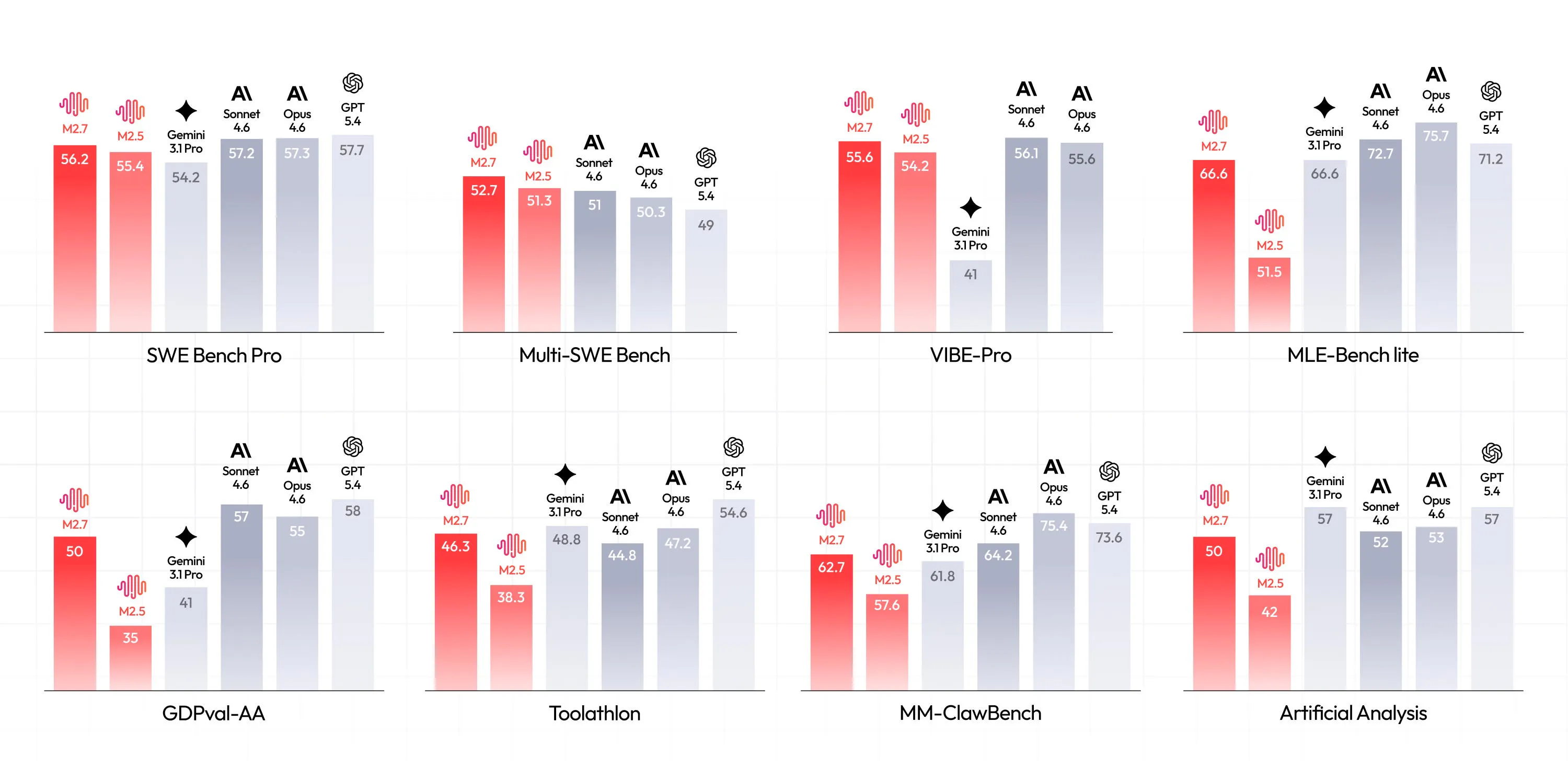
Launched last week, open-source frontier model @MiniMax M2.7 scores 56.2% on SWE Bench Pro, converging towards the best proprietary models like @Claude by Anthropic Opus 4.6.
How do they compare in practice? The @Kilo Code team just ran both models through three coding tasks to see if the benchmark numbers hold up. They created three TypeScript codebases, each model received the same prompt with no hints, and they scored each model independently after all tests were complete.
Key takeaways
Both models found all bugs and security vulnerabilities.
Claude Opus 4.6 produced more thorough fixes and 2x more tests.
MiniMax M2.7 delivered 90% of the quality for 7% of the cost ($0.27 total vs $3.67).
The gap between open-weight and frontier models is shrinking with every release. In another thread on the best AI coding models, [1] some comments rightly suggested finding a balance between performances and prices.
Time to switch?
Replies
ClawSecure
@fmerian The 90% quality at 7% cost finding is the most important data point here. For most production coding tasks, that's a no-brainer. But that remaining 10% matters a lot depending on what you're building.
We use multiple models internally across different workflows and the real answer is never "switch entirely." It's about routing the right task to the right model. Complex architecture decisions, security-sensitive code, and anything requiring deep contextual reasoning, that's where the frontier models earn their cost. Boilerplate generation, refactoring, test writing, and routine bug fixes, that's where the cost-efficient models shine. The 2x more tests from Opus is a good example. If you're building security infrastructure where test coverage directly impacts trust, that's worth the premium. If you're scaffolding a CRUD app, it's not.
The real unlock isn't picking one model. It's building workflows that route automatically based on task complexity and risk level. The teams that figure out intelligent model routing first are going to have a massive efficiency advantage over teams that are still debating "which model is best" as if it's a single answer.
The gap shrinking this fast is great for the entire ecosystem. Competition drives everyone forward. Congrats to the MiniMax team.
Benchmarks are getting closer, but real-world usage still feels very different.
I’ve noticed the gap shows up more in consistency and edge cases than raw capability.
Curious what others are seeing in production.