

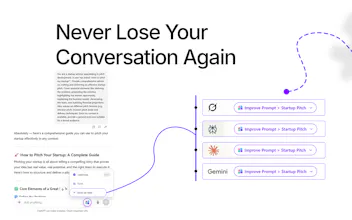
Stop explaining yourself to every AI like it's the first day of school. Over 1 billion users repeat the same context everywhere. AI Context Flow lets you save it once, and use it anywhere: ChatGPT, Claude, Gemini, and more. Smarter chats, zero repetition. Finally.
Interactive



Free Options
Launch Team / Built With






Ancher
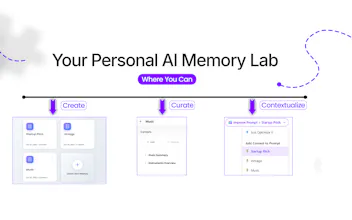
AI Context Flow
@vincentwu800 Thanks! Yes, developer context management is absolutely in the roadmap. We're soon dropping extensions for Claude and ChatGPT desktop, along with a VS Code extension.
RiteKit Company Logo API
@hira_siddiqui1 An idea for you: you might provide an organized library of common language chucks to include in prompts. I feel like a lot of us are just guessing. Maybe start with product? service? Care to choose your Technologies, data sources, etc.?
AI Context Flow
@osakasaul we will be adding meta-settings on individual memory buckets soon. So this is on the roadmap!
Termdock
Congrats on the launch. This is a real pain point finally getting treated.
As someone who works with AI daily and builds with it, I bounce between ChatGPT, Claude, and Gemini all the time. The tiring part isn’t the models. It’s retyping project context, brand voice, and tech details over and over. AI Context Flow turns that into save once, use anywhere. That angle lands.
Your memory approach makes sense in practice. Keep the last turns. Summarize the middle so decisions and facts survive. Use semantic vectors for the deeper stuff. Separate queries from data so questions don’t leak into “things to remember.” These are the traps people hit in real workflows.
For people who work across tools, the mental load drops. Fewer background paragraphs. More attention on the problem at hand. Looking forward to what you ship next.
AI Context Flow
@hcyt exactly! you explained it better than I could :)
Hope you enjoy using the product!
Congrats on the launch! Does it only apply to chrome or also applicable on other browsers?
AI Context Flow
@yuzulele09 it works on Chrome, Brave, Opera and Edge browsers currently.
Support for Mozilla is on the roadmap.
That's really interesting idea. Is there an app for it?
AI Context Flow
@s_muneeb not an app yet, but a lot of people have been asking for mobile support, so we are discussing it internally.
We do have MCP servers that we will launch soon.
You will have a lot of data about people! How do you store it?
AI Context Flow
@alextroitsky so glad you asked this!
So, the data is stored in vector dbs but is end-to-end encrypted and processed in Trusted Execution Environments (TEEs) - so only the user has ownership of their data and can decide where do they divulge which information.
Agnes AI
Very interesting concept! AI memory is getting more and more attention. Just curious - how do you index different memories context?
AI Context Flow
@cruise_chen I'm so glad you asked, because we've built a sophisticated multi-layered memory indexing system that mimics how human memory actually works.
Here's how we index different memory contexts:
1. Three Tiers of Memory (Like Human Memory)
- Short-term memory: We preserve the last 3 conversation turns verbatim - this is your "working memory" that keeps the immediate context fresh
- Mid-term memory: Older conversations get intelligently summarized using LLM, extracting key facts, decisions, and entities - think of it as your brain consolidating information while you sleep
- Long-term memory: All uploaded documents and contexts are converted to semantic vectors (1024-dimensional embeddings using BGE-large-en-v1.5) and stored in AWS S3 Vectors for retrieval
2. Intelligent Query-Data Separation
Before indexing, we use LLM to analyze user input and separate it into:
QUERY: What they're asking
DATA: What they're providing
This prevents "memory pollution" where questions get mixed with actual information you want to remember.
3. Multi-Tenant Isolation
Every memory is indexed with hierarchical metadata:
userId → profileId → context/file → chunks
This means your memories are completely isolated per user and per profile (like having separate notebooks for different projects).
4. Semantic Chunking & Retrieval
Documents aren't stored as raw text - we:
- Break them into semantic chunks
- Generate vector embeddings (capturing meaning, not just keywords)
- Use cosine similarity for retrieval (finding conceptually related content, even with different wording)
5. Context-Aware Optimization
We dynamically optimize what memory to use based on:
- Token budget (no overwhelming the AI with too much history)
- Semantic relevance (only pull memories that matter for the current query)
- Conversation continuity (balance between efficiency and context preservation)
The magic? Unlike traditional keyword search, our vector-based indexing understands meaning.
Ask "What's my Python code for authentication?" and it'll find your login implementation even if you never used the word "authentication" in your original document.
It's serverless, scales automatically, and because we're using AWS S3 Vectors, there's no infrastructure to manage - just pure memory intelligence!
Hope this gives you a sense of how much work has gone into this seemingly small memory extension!
Would love your feedback if you are deep into the AI memory space!