
Launched this week

Magine
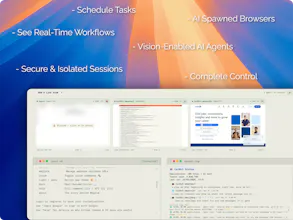
Spawn vision-enabled AI agents autonomously browsing the web
157 followers
Spawn vision-enabled AI agents autonomously browsing the web
157 followers
A cloud of orchestrated, vision-enabled AI agents - autonomously browsing the web like a human would. /\_/\ ( ^.^ ) -> visit magine.cloud = " = Magine AI is purposely built for autonomous zero-human interference where AI can now see, dream, train in real-time, and think like humans where the internet will be for bots humans are the watchers.







Magine
Magine
PS: Thanks to Magine for scheduling its own launch😉
Flowtica Scribe
@sagar4nfs PPS: And for pitching itself to me! 🤖
@sagar4nfs Loving the vision-powered catbots. Quick test: How reliably does it handle dynamic sites like Product Hunt leaderboards (e.g., scraping today's top launches into a summary)?
Magine
Thanks!@swati_paliwal Its amazing how quickly you figured out what catbots do. And yes, it handles dynamic sites like Product Hunt quite well as i explained here (below): https://www.producthunt.com/products/magine?comment=5239224
The only areas where it can occasionally struggle are login flows and, very rarely, paywalls (mostly on X/Twitter and Reddit).
Can it constantly track a list of my competitors and keep giving me updates on the pages that are launching everyday?
Magine
@subhasis_sahoo1 Anywhere.......Anytime. You name the use case - Magine gets it done. 😄 Only catch? It eats tokens like crazy… working on that next.
And hey, thanks for being here early, you’re part of this launch now.
Magine
@subhasis_sahoo1I’ll tell you one case... I was listening to my favorite songs when I watched Magine write an entire email to one of our hunters as we were launching this week. It extracted the hunter's email from PH & composed the entire email from my Gmail and sent him successfully, even scheduling a follow-up mail for future collaboration in my draft.
Proof:
Running vision-based agents for web monitoring is something I've thought about a lot - the fragility of DOM-based approaches is a real pain. One thing I haven't seen addressed much: how do you handle the token cost at scale if you're running continuous frame capture across multiple concurrent agents? That feels like it could get expensive fast.
Magine
@mykola_kondratiukGenuinely, optimizing this was very tough. This includes minimal token usage by not processing every frame blindly- it uses adaptive sampling (event-driven frame capture..) and only invokes heavy vision reasoning when there’s a meaningful UI change or decision point ..e.g CAPTCHAS or getting user's credentials. On top of that, a Mixture-of-Experts pipeline, routing lightweight perception tasks to cheaper deployed models and reserving high-cost models only for complex reasoning, which keeps multi-agent runs cost-efficient. In parallel, it maintains its own short-term and long-term memory, along with context caching to track UI elements and [STEPs] (which are the crucial part of workflow).
Adaptive sampling makes sense - triggering on state changes rather than constant polling is the right call. Good to know the token problem is actually solved and not just papered over.
curious about the vision aspect - are these agents actually processing visual elements on pages or just seeing the DOM structure? the idea of AI agents that can navigate sites like humans do is fascinating, especially for automating tasks that require visual context recognition.
Magine
@piotreksedzik Yes, The SDAs are actually processing visual frames, not just relying on DOM. We do use light DOM grounding when helpful, but the core loop is vision-first - understanding layout, context, and UI state directly from the screen, which is why they stay resilient to UI changes.
@sagar4nfs Super cool. So, if I have a Playwright script that suffers from this DOM hell you speak of, constantly breaking, could your agent analyze the script and recreate it using vision?
Magine
@mark_brandon2 You’re already thinking in the right direction 🙌 The idea is that even if it breaks right now, it can recover and correct itself by learning from its own mistakes. Authentication might fail on the first attempt for some users, but it usually succeeds on retry without throwing errors. I’m currently working on improving long-term memory for UI/DOM patterns so it becomes more consistent and reliable across all users.
Congrats on shipping this, the vision-based approach vs DOM scraping is the right bet. One question: once your agents are running scheduled tasks autonomously, how do you get visibility into what they're actually doing at the prompt/response level? We ran into this with local agent stacks and it became a serious blind spot. That's what Veil-Piercer solves, curious if browser agents hit the same wall.
Magine
@lauren_flipo Yeah, this “black box” problem is very real. To handle that, Magine records step-level action traces - every frame, decision, and action is logged as part of an “action stream.” So instead of just prompt/response logs, you get:
-what the agent saw
-how it reasoned
-what it did (clicks, inputs, navigation)
Think of it more like a replayable execution timeline rather than a traditional LLM log - which helps avoid that blind spot you mentioned.
The "sight-driven" approach is the right bet. APIs break every time the UI changes, but vision-based agents adapt the same way humans do. We're working on something similar for desktop automation (not just browser) and the reliability difference between DOM scraping and screen vision is night and day.
How does Magine handle sites with heavy dynamic content like infinite scroll or lazy-loaded elements? That's usually where vision agents struggle.
Magine
@mihir_kanzariya Love this - totally agree on the reliability shift. For dynamic content, Magine uses iterative perception loops (scroll → observe → re-evaluate) with temporal awareness, so it behaves more like a human exploring rather than a one-shot vision guess.