

Metabase
Open source Business Intelligence and Embedded Analytics.
4.9•24 reviews•826 followers
Open source Business Intelligence and Embedded Analytics.
4.9•24 reviews•826 followers
Metabase is the easy-to-use, open source Business Intelligence tool that lets everyone work with data, with or without SQL. Make self-service analytics finally happen in your org, or embed Metabase in your app for customer-facing analytics.
This is the 4th launch from Metabase. View more

Metabase Data Studio
Launching today
AI analytics is only as good as the context you give it. Without a semantic layer - a unified, shared definition of metrics, segments, and business logic - AI (and everyone else) is guessing at what "active user" or "revenue" means at your company.
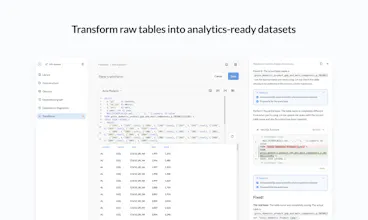
Data Studio is the analyst workbench where that foundation gets built. Define metrics once. Transform raw tables using SQL or Python. See dependencies before changing anything. Publish what's trusted to your Library. Then get reliable answers from AI






Free Options
Launch Team / Built With









This is my favorite project that Metabase launched, and I use it every day now. It's a set of tools to run your entire data stack inside Metabase: transforms, definitions, lineage, everything.
Here's how I use it every day:
- Write SQL (and sometimes Python) transforms and save results straight to the database: like cleaning up messy user signup data and combining it with referral info to make a new table I can query everywhere.
- Define metrics once so I don’t have to rethink “what counts as active users” every time: now everyone on the team uses the same definition.
- Create clean tables I trust: for example, a revenue table that I know is accurate and ready for dashboards without extra checks.
- Trace numbers back when something looks off: like seeing exactly which transform or question a dashboard number came from instead of guessing.
- Catch issues early: if a column got renamed and a query breaks, I know immediately which dashboards are affected before anyone asks “why is this number different?”
Everything in one place.
Metabase
We're excited to announce that we've launched a new, simple way to clean up your data structure as you grow. Not all companies needed transformations, semantic layers and metadata curation in the past as agents. However, as agent powered analytics become a primary way for people to work with data, a clean data layer matters more and more. Data Studio is how we think you should create it!
@sameer_alsakran How does Metabse handle real-world messy data scenarios, like inconsistent schemas across growing datasets or auto-fixing agent-specific quirks in metadata?
Metabase
@swati_paliwal Depends on what you mean by inconsistent schemas. The key idea is that there should be a single layer that either a human or an agent can understand before you throw natural langauge querying at it. This layer should be solid -- it is the foundation, and should be versioned, reviewed and annotated. There are lots of ways to edit this layer (generated sql, mcp, etc), but the key thing we're doing is extracting this from our internals and making it controllable.
The "what does active user mean" problem is real and expensive. Every company I have worked at has had at least three competing definitions living in different dashboards. The shared semantic layer approach makes sense - it is the same problem that good data teams solve manually, just formalized. How does Data Studio handle it when business definitions legitimately change over time - does it version the metric or just update in place?
Metabase
@mykola_kondratiuk Version. Definitely version =)
Good answer. Versioning is the only way to not break trust in the metric retroactively.
Metabase
You know that moment when someone asks "how many active users do we have" and three people give three different numbers?
Yeah, we fixed that ✌️
The dependency graph feature is what sells this for me. Been burned too many times by renaming a column upstream and only finding out days later when a dashboard breaks. Having that visibility built into the same tool where you define metrics feels right — no more duct-taping dbt + Looker + docs together.
Metabase
@letian_wang3 We feel your pain. We hope this saves you some time and duct tape
Data transformation in Metabase? Wow! 🤩
Metabase
@tatyana_avlochinskaya Dreams do come true ;)
Flux
Great to see Metabase still going strong. I used it a couple years ago on a personal project and I liked it a lot.
Metabase
@gregdingle thanks for your support!