

Sudo is a unified API for LLMs — the faster, cheaper way to route across OpenAI, Anthropic, Gemini, and more. One endpoint for lower latency, higher throughput, and lower costs than alternatives. Build smarter, scale faster, and do so with zero lock-in






YouMind
Congrats on the beta launch — excited to see a unified API tackling routing, cost and context management.
Quick question: what's the latency improvement I can expect when switching from OpenRouter or a single-provider setup, and do you expose per-model routing logs for debugging? Also curious about pricing predictability once billing features go live — will there be rate caps or alerts for end-user charges?
Sudo AI
thanks @jaredl!
On some models, we perform over 50% faster than OpenRouter on the base provider (OpenAI, Anthropic, etc). You can see our benchmarks on the GitHub.
We do not (currently) have routing logs, but that is a feature we could implement soon. Are inference logs something that you'd be interested in to help your development needs?
There won't be pricing caps -- you can set pricing rates to whatever you want. The end-user will pay the price you define for them. As for usage caps, we are looking into allowing per-API-key rate limits, so you can issue a key for each end-user or agent you deploy, with that key having a hard cap on usage. We would also allow you to set a usage limit for your subscribing users, such that they won't go above the usage amount you alot to them as part of their subscription.
What are your most outstanding demands when it comes to billing end-users?
Congrats on the launch, guys! Looks like a great tool and quality product.
As a builder in AI, I appreciate the vision beyond routing to incorporate CMS and monetization functionality. This has potential to become a vibrant dev platform in addition to being an optimized and convenient routing tool!
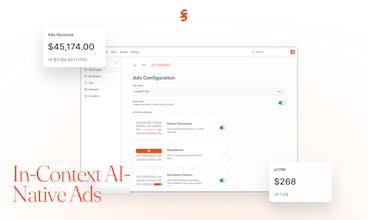
Looking to try it out over the next few days and weeks. Could you elaborate on the Ads feature set and how it works?
Congratulations on the launch!! What an accomplishment.. I already have a few friends recommending me this product!! Really love how much faster routing will be.
Sudo AI
@jasmine_karkafi Thanks Jasmine!! What are you using router for / what are you building?
What a lovely product @kevin @0xphoenice @ventali 🔥🔥🔥
Sudo AI
@kevin @0xphoenice @bhautikk Thanks so much for your kind words Bhautik!
This is huge 👏
As builders, we’ve felt the pain of juggling multiple APIs and the unpredictability of inference costs. The idea of one unified endpoint with routing + context management + billing baked in is a game-changer for anyone trying to scale AI products sustainably.
Excited to see how the real-time billing and memory-aware agents evolve, that combo feels like it could unlock a lot of new use cases. Wishing you an amazing launch day!
Sudo AI
@ayushi_mishra10 Thanks so much 🙏 Really appreciate the encouragement! Out of curiosity, for your own use cases, which of those feels like the bigger unlock — smoother infra (routing/cost) or enabling new app behaviors (billing/context)?
@ventali I’d say infra first, routing + cost predictability solve the pain we feel every day. But long term, the memory + billing combo is where the real magic happens. That’s what unlocks new apps!
Great job girllll and the team!!! So happy to see another Ventali's creation 🥰 🥳, just can't wait to try it out!
Sudo AI
@yolandawang 🫶🏻🫶🏻🫶🏻
Score with Friends
this could’ve helped me a lot when i was building an llm app for long covid sufferers to manage their symptoms. I had to roll memory by myself, and never got around to billing or referrals (aka ads) because it was too much work for a side project even tho we had good usage. wish i was building an llm project now so i could use Sudo! great idea to all in one all the basic painful crap
Sudo AI
@djkgamc precisely! There are many people in this situation of building consumer AI solutions but don't have the bandwidth to go the extra mile to roll memory, save context, bill users, and monetize their apps. That's what we're trying to solve
When you built your LLM app, what was your #1 pain point with the AI integrations? Was it retries, uptime, latency, context management, or something else?