

Waydev
Engineering intelligence for the AI era
1.6K followers
Engineering intelligence for the AI era
1.6K followers
Waydev is the measurement layer for AI-written code. We track AI adoption, AI impact, and AI ROI across the full SDLC — from the first token consumed to the line shipped in production. Nine years building engineering intelligence. YC W21. Fortune 500.
This is the 10th launch from Waydev. View more

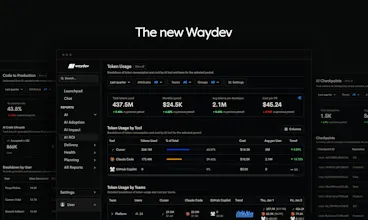
The New Waydev
Launched this week
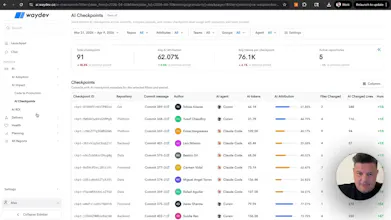
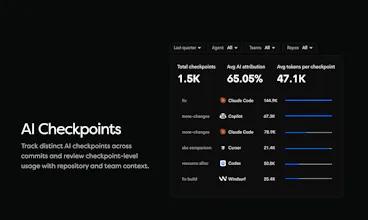
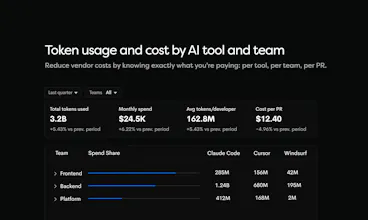
AI agents write code. Most teams cannot tell you what percentage actually ships. Waydev tracks agent-generated code from IDE to production with AI Checkpoints: which agent, tokens consumed, cost per PR, acceptance rate, deployment status. Per team, per repo, per vendor. Compare Copilot, Cursor, and Claude Code on what reaches your customers. Measure cost per shipped PR and AI ROI. Ask the Waydev Agent anything.

Free Options
Launch Team


Waydev
Hey Product Hunt 👋
I am Alex, founder of @Waydev Nine years of building engineering intelligence. I have never seen a shift like this one.
AI agents are writing your code. Nobody audits the output.
4% of public GitHub commits are already authored by Claude Code. Companies are spending up to $195 per developer per month on AI coding tools. Almost none of them can prove the spend is working.
That is the gap we rebuilt Waydev to close. The new platform measures the full AI SDLC:
AI Adoption — which tools your teams use, what you spend per vendor, per team, per repo
AI Impact — follow AI code from IDE to production. See where it ships and where it dies
AI ROI — cost per PR, cost per shipped line, tokens consumed vs code shipped
AI Checkpoints — commit-level attribution. Which agent, how many tokens, what percentage was AI
Waydev Agent — ask anything. Closes the loop by feeding insights back to your AI through MCP
AI adoption was the easy part. Proving what AI actually changed in production is the hard part. That is what we built.
In the comments all day. Ask me anything.
— Alex
@alex_circei, congrats to you and the team! This cuts to something most teams aren’t ready to admit yet: we’ve dramatically improved code generation, but not accountability. Measuring AI adoption is easy, but measuring whether that code actually survives in production is the hard and far more important problem. The focus on commit-level attribution and metrics like cost per PR or shipped code is directionally right, even if imperfect. Without that layer, AI spend is just a growing line item with no clear tie to outcomes.
What’s especially interesting is closing the loop, feeding these insights back into the agents themselves. That’s where this shifts from analytics to a self-improving system. The challenge will be balancing useful visibility with developer trust. This has to feel like system optimization, not surveillance. If you get that right, this starts to look like the observability layer for AI-generated code. That’s a category worth defining early. Godspeed :-)
Waydev
@savian_boroanca Thanks Savian, really appreciate this.
That’s exactly the bet we’re making. AI adoption is easy to report, but the real question is whether that code survives review, ships to production, and actually improves outcomes.
We also believe the next step is closing the loop, turning those signals into feedback for both teams and agents, without making it feel like surveillance. It has to help engineering organizations optimize the system, not police developers.
Still early, but we think this is a missing layer in the market, and a category worth building.
@alex_circei For teams blending human + AI code say, junior devs iterating on agent output, how does Waydev surface the "human lift" vs pure AI PRs? Does it flag where devs spend most time reviewing/rejecting AI suggestions; those subtle quality gates that spending alone misses?
Waydev
@dayal_punjabi That’s exactly the gap we’re trying to solve.
Waydev separates AI-assisted, agent-driven, and human work, then shows what happened after the code was written: review time, rework, cycle time, deploy frequency, and incident correlation. That makes the human lift visible, not just the volume of AI-generated code.
So if a junior dev or agent opens a PR, you can see whether humans had to heavily review, rewrite, slow down, or stabilize it before it actually shipped.
For suggestion rejection at the IDE level, it depends on the source integration, but our main point is this: AI usage alone is not the truth, production outcomes are.
Product Hunt
Waydev
@curiouskitty Great question. We made a few deliberate product choices to avoid turning Waydev into a commit/LoC scoreboard.
First, we do not optimize around raw activity metrics. Commits, lines of code, PR count, and similar signals can be useful as context, but they are easy to game and dangerous when treated as outcomes. We focus much more on system-level flow, quality, and delivery signals like cycle time, review time, deployment frequency, change failure rate, rework, incidents, and what actually ships to production.
Second, we push measurement up from the individual to the team, repo, and org level. The goal is to understand how the system performs, where work gets stuck, and whether tooling, process, or AI adoption is improving outcomes. Not to rank engineers.
Third, we connect metrics instead of showing them in isolation. A spike in PR volume alone tells you very little. But PR volume plus longer review time, higher rework, and more incidents tells a very different story. That is how you reduce metric gaming, by making tradeoffs visible.
Fourth, we recommend companies use Waydev for coaching and operating rhythms, not performance management. The best rollouts are for engineering leaders, not as a scorecard for individual compensation discussions. Use it to ask: where are the bottlenecks, which teams need support, what changed after adopting AI tools, what is improving, what is getting worse?
My simple rule is this: if a metric can be easily gamed, it should never be the goal. It can be a signal, but never the target.
So the operational model we recommend is:
measure teams and systems, not individuals
look at outcome bundles, not single vanity metrics
use trends and before/after analysis, not snapshots
combine quantitative signals with qualitative context like DevEx feedback
never use one metric as a proxy for engineer quality
That is how you get value from engineering intelligence without creating Goodhart-law behavior.
Most team track usage , but not what actually makes it to production. This kind of visibility could really help cut wasted spend . Curious if it also highlights why some AI generated PRs don't get shipped?
Waydev
@caleb_bennett1 Exactly. Most AI dashboards stop at usage. The real question is what gets merged, shipped, and creates value. And yes, this kind of visibility should also show where AI-generated PRs get stuck, in review, rework, or abandonment, which is where a lot of wasted spend hides.
@caleb_bennett1 Really good point
Finally something that looks at actually measuring productivity beyond just lines of code. With AI agents, generating code is becoming the easy part, but the more important question is what actually makes it through review, ships to production, and creates durable value. Otherwise we risk confusing velocity of spitting code with actual progress.
This feels like the right lens for understanding AI’s real contribution to engineering teams. The one question I'm still trying to figure out and I'd love your perspective: how do you connect these engineering metrics (output) with the business KPIs (actual business outcome)?
Waydev
@cborodescu Chip, exactly. That is the trap, AI can increase code volume far faster than it increases delivered value.
The way we think about it is by treating engineering metrics as leading indicators, then tying them to business outcomes at the team, initiative, and product level. For example:
cycle time, review time, deployment frequency, and rework rate show how efficiently value moves through the system
incidents, rollback rate, and change failure rate show the quality cost of that speed
then you connect those signals to business KPIs like feature adoption, customer retention, revenue impact, SLA performance, and cost to deliver
So the real question is not “did AI generate more code?” but “did AI help this team ship the right work faster, with less risk, and with better business results?”
That is the layer we think is still missing in most of the market.
Token consumption tracking is interesting — how does that work in practice with something like Claude Code, which runs autonomously and can spin up multiple sub-agents mid-session? Are you capturing tokens at the session level, per file touched, or per PR? The attribution question gets messy fast when one 'task' spawns 40 tool calls across 3 agents.
Waydev
@sounak_bhattacharya Great question. In practice, session-level token counts alone get noisy very fast, especially with autonomous agents and sub-agents.
The way we think about it is:
session/run = execution context
tool calls / sub-agents = child events inside that context
PR / merged changeset = primary attribution layer
production outcome = the layer that actually matters
So if one task spawns 40 tool calls across 3 agents, we would not treat those as 40 separate “units of value.” We roll them up into a lineage, then attribute the consumption and activity to the PR, repo, engineer/team, and eventually to what shipped.
Per-file is useful as supporting detail, but not as the source of truth. The cleanest practical model is to preserve the raw trace, then normalize attribution at the PR / merge / deployment level.
Otherwise you get a lot of activity data, but no real answer to whether the spend produced better outcomes.
That is also why we care less about token volume in isolation, and more about token spend tied to cycle time, rework, deploy frequency, incidents, and production impact.
This is a question I've been trying to answer internally for months - what percentage of AI-generated code actually makes it to production, and is it saving us time or creating tech debt we'll pay for later. The "cost per shipped PR" metric is smart because it ties AI usage directly to business output instead of vanity metrics like "lines generated." Curious how it handles the gray area - like when a dev uses Copilot to scaffold something, then rewrites 60% of it. Does that count as AI-written or human-written? That attribution problem seems really hard to solve cleanly.
Waydev
@ben_gend That is exactly the hard part, and I do not think the right answer is a binary label like AI-written vs human-written.
In your example, if Copilot scaffolds something and the developer rewrites 60% of it, that work should be treated as mixed contribution. The useful question is not who gets full credit for the lines, but how much AI-assisted code survives the editing, review, merge, and production path, and what happens after it ships.
That is why we think attribution has to be modeled across the full chain: suggestion, acceptance, edit distance, PR, merge, and production outcome. Once you do that, you can separate raw AI output from retained AI contribution and then connect it to speed, rework, incidents, and maintainability. Otherwise teams end up optimizing vanity metrics instead of shipped value.
This is solving a real problem I hit as CTO. When we scaled from 15 to 120 engineers, we tracked everything - velocity, cycle time, PR throughput - but none of it told us whether the work actually mattered. AI tools make this gap even wider because raw output volume goes through the roof while the signal-to-noise ratio drops. Measuring from token to production instead of just counting lines is the right frame. Curious how you handle the attribution problem when a single feature touches both human-written and AI-generated code across multiple PRs.
Waydev
@avrisimon That was the core problem for us too. Traditional engineering metrics were built for a world where humans wrote all the code, so once AI starts increasing output, volume stops being a reliable proxy for value.
On attribution, we do not try to force a fake binary answer at the feature level. In reality, most shipped work is mixed across human and AI contributions, often across multiple PRs. The right way to handle it is to track provenance at the session, commit, and PR level, then aggregate it at the feature or delivery outcome level. That lets you see not just how much AI touched the work, but whether AI-assisted work led to faster shipping, less rework, fewer incidents, and better long-term outcomes in production.
So the goal is less ‘who wrote every line’ and more ‘what mix of human + AI contribution produced the shipped result, and was it actually better?